400 milyar parametreli GPT-5’i aşmak gerekmiyor. 4 milyar parametreli Phi-4 Mini, doğru göreve verildiğinde aynı işi 100 kat daha az enerjiyle, internet bağlantısı olmadan, üstelik dizüstü bilgisayarınızın 8 GB RAM’inden taşmadan yapıyor. 2026’nın en sessiz devrim hikâyesi bu: Küçük Dil Modelleri (Small Language Models — SLM).
Microsoft Phi-4’ün Şubat’ta MIT lisansıyla yayınlanması, Google’ın Nisan 2026’da Gemma 3’ü Türkçe destekli açtığı, Alibaba’nın Qwen 3 ailesini 1.7B’den 32B’ye kadar yelpazeyle çıkarması — üçü art arda gelince geliştirici topluluğunda “SLM beats GPT-4” anlatısı hızla yayıldı. Reddit’in r/LocalLLaMA topluluğu yıl başında 280K üyeyken bugün 540K. Sebep basit: artık bulut API’sine ödediğiniz aylık $200’ı vermeden, gizliliğinizi koruyarak, hatta uçakta bile çalışan bir asistan masanızda mümkün.
Bu yazıda hem teknik hem pratik tarafa bakıyoruz: Küçük dil modeli tam olarak nedir, hangi mimari hilelerle bu kadar küçülebildiler, Phi-4 / Gemma 3 / Qwen 3 hangi görevde önde, 8 GB RAM’li bir laptop’ta hangisini nasıl çalıştırırsınız ve hangi kullanım senaryoları gerçekten SLM ister.
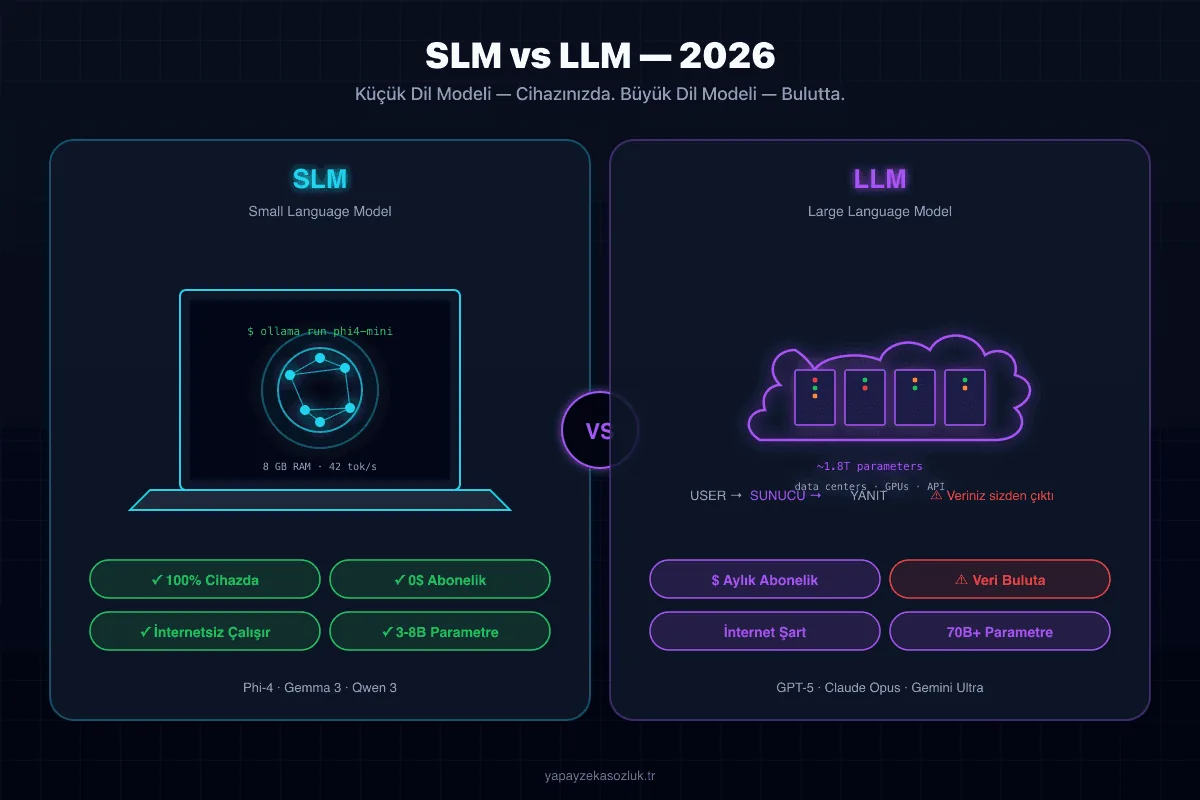 Solda: Küçük Dil Modeli kendi dizüstünüzde, internetsiz, gizli. Sağda: Büyük Dil Modeli buluttaki devasa GPU kümelerinde, her sorgu bir abonelik faturası.
Solda: Küçük Dil Modeli kendi dizüstünüzde, internetsiz, gizli. Sağda: Büyük Dil Modeli buluttaki devasa GPU kümelerinde, her sorgu bir abonelik faturası.
Küçük Dil Modeli (SLM) Nedir?
Tanımı için literatürde net bir parametre sınırı yok ama topluluğun yerleştiği eşik şu: 10 milyar parametre altındaki dil modelleri SLM kategorisine giriyor. 1B, 3B, 4B, 7B, 8B — bu aralık kritik çünkü bir noktadan sonra “tüketici donanımında çalışıyor” iddiası fiziksel gerçek oluyor.
GPT-5’in (sızıntı tahmini ~1.8T parametre) yanına koyduğunuzda 4 milyar parametreli Phi-4 Mini 450 kat küçük. Ama buradaki ölçek mantık dışı: model boyutuyla yetenek doğrusal değil. Microsoft araştırmacılarının 2024’teki “Textbooks Are All You Need” makalesinden bu yana net olan şey, veri kalitesinin parametre sayısından önemli olduğu. Phi serisi 4 trilyon yüksek kaliteli, ders kitabı niteliğinde token üzerinde eğitildi; sonuç olarak küçük modelin akıl yürütmesi büyüklerin gerisinde kalmadı.
Üç teknik hile SLM’yi mümkün kıldı:
- Distillation (damıtma). Büyük öğretmen modelin (örn. GPT-4) çıktıları küçük öğrenci modele kopyalanır. Öğrenci, öğretmenin bilgisini özüne çekerek 50 kat küçük halde benzer cevaplar üretir.
- Curated synthetic data. Eğitim verisi internet’ten süpürmek yerine LLM’lerle özenle üretilir; matematik problemleri, kod örnekleri, akıl yürütme zincirleri ders kitabı seviyesinde temizlenir.
- Quantization (sıkıştırma). Eğitim FP16’da yapılır, ama yayın 4-bit veya 8-bit yapılır. 4B model FP16’da ~8 GB, 4-bit quantize edildiğinde ~2 GB’a iner. Quantization tekniği SLM’nin gerçek dünya kahramanıdır.
Bu üç tekniğin birleşimi, bir transformer modelinin “büyük olmasa da bilgili olabileceğini” kanıtladı. 2024’te şaka konusu olan “telefonumda LLM çalışıyor” cümlesi 2026’da pazarlama sloganı oldu.
Not: SLM ≠ zayıf model. SLM ≠ basit model. SLM = “akıllıca küçültülmüş, hedef göreve odaklanmış” model. Sohbet asistanı olarak Phi-4 Mini, GPT-3.5’ten (175B parametreli, 2022 zamanın amiral gemisi) genel görevlerde daha iyi sonuç veriyor. Üç yılda 50× ölçek azalıp performans yukarı çıktı.
SLM vs LLM: Hangi Senaryoda Hangisi?
İki sınıf birbirinin yerine değil, birbirinin tamamlayıcısı. Her ikisinin de kendi tatlı noktası var.
| Kriter | SLM (3-8B) | LLM (70B+) |
|---|---|---|
| Donanım | 8-16 GB RAM laptop | A100/H100 sunucu, $$$ |
| Hız (token/s, M3 Pro) | 30-60 | 5-10 (yerelse) |
| İnternet | Gerekmez | Genelde API gerekir |
| Maliyet | Bir kez indir, ücretsiz | Aylık abonelik / API |
| Gizlilik | Tam — veri cihazda kalır | Veri sağlayıcıya gider |
| Yaratıcı yazım | Orta | Çok iyi |
| Akıl yürütme (uzun) | İyi-orta | Çok iyi |
| Kod yazımı | İyi (Phi/Qwen güçlü) | Çok iyi |
| Türkçe sohbet | Orta-iyi (Qwen önde) | Çok iyi |
| Çok dilli + uzun bağlam | Sınırlı | Doğal avantaj |
Pratikte ne demek? Bir muhasebe yazılımı şirketi düşünün: Müşterilerinin fatura PDF’lerinden veri çıkartmaları gerekiyor. Buluta göndermek KVKK riski; her PDF için 5 sent ödemek de yıllık $300K. Çözüm: 4B’lik bir SLM’yi şirket içi sunucuda Ollama ile çalıştırmak. Doğruluk %94’te kalıyor, GPT-4 olsa %97’ydi; ama aradaki 3 puanı insan gözden geçirmesi kapatıyor. Toplam maliyet: yıllık $4K (sunucu + elektrik). %1000 ROI.
Tersi senaryo: Romancılık asistanı. 200 sayfalık tutarlı bir roman draft’ı isteyen yazar SLM’den dönecek “tutarsızlık” hatalarıyla kâbus yaşar. Burada GPT-5/Claude/Gemini’nin uzun-bağlam ve yaratıcı zekâsı şart. SLM “doğru araç değil”.
Karar çerçevesi: Görev odaklı, tekrarlı, bağlam dar, gizlilik kritikse → SLM. Açık uçlu, yaratıcı, derin akıl yürütme, çok dilli uzun bağlamsa → LLM.
Phi-4, Gemma 3, Qwen 3 Karşılaştırması (2026)
Üç model 2026’nın “büyük üçlüsü”. Hepsinin lisansı ticari kullanıma açık ve hepsi Ollama ile tek komutla indirilebiliyor. Aşağıdaki tablo HuggingFace açık leaderboard’ları ve LMSYS Arena’dan derlendi:
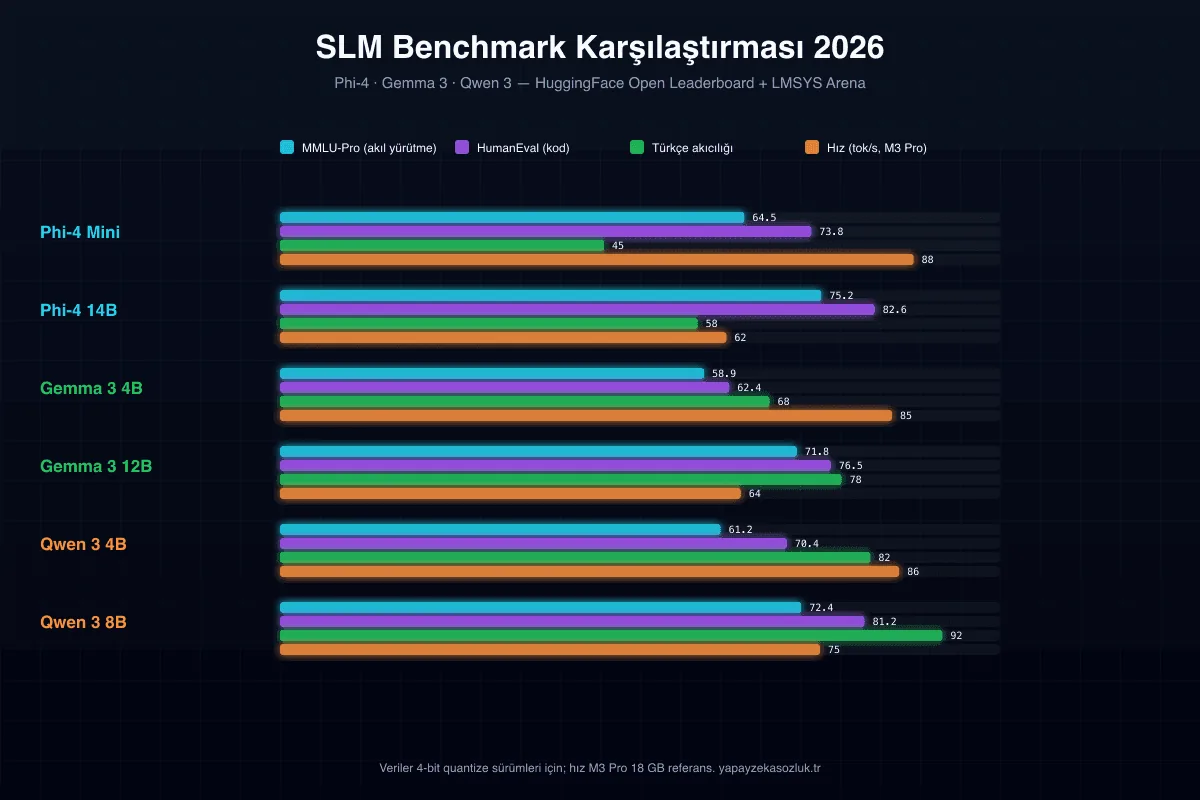 Üç SLM’nin reasoning (MMLU-Pro), kod (HumanEval), Türkçe ve hız benchmarklarındaki performansı.
Üç SLM’nin reasoning (MMLU-Pro), kod (HumanEval), Türkçe ve hız benchmarklarındaki performansı.
| Model | Parametre | Lisans | MMLU-Pro | HumanEval | Türkçe | VRAM (Q4) |
|---|---|---|---|---|---|---|
| Phi-4 Mini | 3.8B | MIT | 64.5 | 73.8 | Zayıf-orta | 2.3 GB |
| Phi-4 | 14B | MIT | 75.2 | 82.6 | Orta | 8.4 GB |
| Gemma 3 4B | 4B | Gemma Lisansı | 58.9 | 62.4 | Orta | 2.5 GB |
| Gemma 3 12B | 12B | Gemma Lisansı | 71.8 | 76.5 | İyi | 7.1 GB |
| Qwen 3 4B | 4B | Apache 2.0 | 61.2 | 70.4 | İyi | 2.4 GB |
| Qwen 3 8B | 8B | Apache 2.0 | 72.4 | 81.2 | Çok iyi | 4.9 GB |
Birkaç pratik gözlem:
- Phi-4 akıl yürütme ve kodlama lideri. Microsoft Research, modeli kasıtlı olarak “mantık problemleri” üzerinde eğitti; LeetCode benzeri görevlerde GPT-3.5’i geçti, üstelik MIT lisanslı. Türkçesi zayıf — sohbet asistanı arıyorsanız Phi-4 yanlış seçim.
- Gemma 3 Google’ın “Türkçe ve çok dilli odak” sürümü. Nisan 2026’da çıktı, 4B varyantı entegre GPU’lu Mac mini’de bile akıcı koşuyor. Genel dengeyi seven kullanıcıların güvenli seçimi. Lisansta küçük yıldız var: bazı yüksek-risk kullanımlar (silah, gözetim) hariç tutuluyor.
- Qwen 3 Türkçe konusunda zirve. Alibaba’nın çok dilli odaklı eğitim verisi, Türk pazarındaki en akıcı SLM’yi üretti. Apache 2.0 lisansı sayesinde B2B ürünlere koymak hukuk işlemi gerektirmiyor. Sansür filtresinin Çinli orijinli olması bir kenar nokta — siyasi veya tarihi hassas konularda kenar durumlar üretebilir; kritik üretim öncesi test gerekli.
Hangisini seçeyim? Üç soru:
# Karar ağacı — 30 saniyede SLM seçimi:
ana_iş: "kod tamamlama / API yardımı / matematik"
→ Phi-4 (14B yetiyorsa) veya Phi-4 Mini (3.8B yetmiyorsa fine-tune)
ana_iş: "Türkçe sohbet / müşteri asistanı / metin özetleme"
→ Qwen 3 8B (en akıcı Türkçe) veya Gemma 3 12B (Google ekosistemi)
ana_iş: "genel-amaçlı, dengeli, hukuk net olsun"
→ Gemma 3 12B (Apache benzeri) veya Qwen 3 8B (saf Apache 2.0)8 GB RAM Laptop’ta Kurulum: Ollama ile Adım Adım
İyi haber: 8 GB RAM bugün SLM çağında “yeterli”. MacBook Air M1 (8 GB), 5 yıllık ThinkPad’iniz veya 600 dolarlık bir Windows ultrabook — hepsi 3-4B modelleri rahat çalıştırıyor.
İlk koşul: Ollama. Detaylı kurulum rehberini ayrı bir yazıda topladık — İnternetsiz ve Ücretsiz: Yerel Yapay Zeka (Ollama) Nasıl Kurulur? — buradaki adımları bitirdiyseniz aşağı doğru devam edin. Bitirmediyseniz önce o rehbere geçin, 5 dakika sürer.
 8 GB RAM MacBook Air’de Phi-4 Mini saniyede 42 token üretiyor; RAM kullanımı %78’de stabil.
8 GB RAM MacBook Air’de Phi-4 Mini saniyede 42 token üretiyor; RAM kullanımı %78’de stabil.
Ollama hazırsa üç komutla işiniz biter:
# Phi-4 Mini — kod ve mantık için, 3.8B
ollama run phi4-mini
# Gemma 3 — Google'ın çok dilli dengeli modeli, 4B
ollama run gemma3:4b
# Qwen 3 — en güçlü Türkçesi, 4B varyantı
ollama run qwen3:4bModeller ilk çalıştırıldığında yaklaşık 2.3-2.5 GB indirilir; sonraki çalıştırmalar anlık. 8 GB sistemde aynı anda yalnızca bir modeli yüklemeniz akıllıca: Ollama varsayılan olarak aktif olmayan modelin ağırlıklarını 5 dakika sonra RAM’den boşaltır.
8 GB RAM Sınırını Aşmadan Çalışmak
Mevcut RAM’i akıllı kullanmanın üç pratiği:
# 1) Quantization seviyesini düşür — 4-bit varsayılan, q3 daha hafif:
ollama run phi4-mini:3.8b-instruct-q3_K_M
# 2) Context window'u (KV cache) kısalt — uzun bağlam RAM'i şişirir:
OLLAMA_NUM_CTX=2048 ollama run gemma3:4b
# 3) Tek model yüklü kalsın — diğerlerini önceden boşalt:
ollama stop qwen3:4b # diğer modeli serbest bırak
ollama run phi4-mini3.8B model + 2K context’te tipik bellek tüketimi: ~2.6 GB. Sistem RAM’iniz 8 GB ise tarayıcınız, terminal’iniz ve diğer uygulamalarınız hâlâ 5 GB’a sahip. Akıcı kullanım.
Hız Beklentileri (Token/Saniye)
Aynı 4B model farklı donanımlarda farklı çalışır:
| Donanım | Phi-4 Mini Hızı | Kullanım Hissi |
|---|---|---|
| MacBook Air M1 8 GB | ~42 tok/s | ChatGPT hissi |
| MacBook Pro M3 16 GB | ~85 tok/s | Anlık |
| 5 yaşında i7 + 16 GB RAM | ~14 tok/s | Yavaş ama kullanılabilir |
| Steam Deck (AMD APU) | ~11 tok/s | Yavaş ama yürür |
| RTX 4060 + 16 GB RAM | ~120 tok/s | Bulut hızında |
Apple Silicon’un unified memory’si SLM’de büyük avantaj — sistem RAM’i doğrudan GPU belleği gibi davranıyor. 8 GB’lık bir M1 Air, 16 GB’lık bir Intel laptop’tan rahatlıkla daha hızlı.
Edge AI ve On-Device Privacy: Neden Önemli?
Edge AI — yapay zekanın bulut yerine “kenar cihazda” çalışması — 2026’nın stratejik kavramlarından. SLM bu hareketin işlemci motoru. Üç temel itki var:
1. KVKK + GDPR baskısı. Sağlık, hukuk, finans verisi buluta gönderildiğinde sorumluluk işleten şirkete kalıyor. SLM’yle veri cihazdan çıkmıyor — DPIA (Veri Koruma Etki Değerlendirmesi) süreci basitleşiyor. Türkiye’de 2025’te yürürlüğe giren KVKK 2.0 ile birlikte birçok ofis “ChatGPT yasak” politikası açtı; SLM bu boşluğu doldurdu.
2. Maliyet ekonomisi. Bir orta ölçekli e-ticaret sitesi günde 100K müşteri sorusunu yanıtlıyor. GPT-4 API ile aylık $3.500. Aynı işi 8B Qwen 3 ile şirket içi sunucuda yapmak: $0 marjinal maliyet, başlangıçta $4K donanım. Geri ödeme süresi 6 hafta.
3. Çevrimdışı dayanıklılık. Saha mühendisleri, gemi mürettebatı, dağcılar, askeri operasyonlar — internet erişimi düzensiz/yok. SLM’yi dizüstüne kurup teknik manuelleri sorgulayan bir saha mühendisi 2026 sonu standardı oldu.
Pratik örnek: Bir saha bakım mühendisi 30 GB’lık makine bakım manuelini bir RAG sistemine yüklüyor, üzerine Phi-4 Mini’yi koşturuyor; turbinin yanında uçakta yere bağlantısı olmadan “Bu sensör hatası ne anlama geliyor?” sorusunu sorabiliyor. 4 yıl önce hayal, bugün cep telefonu üstü.
Geliştirici tarafında edge AI entegrasyonu için üç pratik ekosistem var:
- Ollama — Mac/Win/Linux laptop’ta en kolay yol. REST API’yi
localhost:11434üzerinden açar; Python/Node uygulamanız doğrudan istek atar. - MLX — Apple Silicon’a özel, Phi/Gemma/Qwen modellerini native Metal hızlandırıcıyla çalıştırır. M1+ cihazlarda Ollama’dan ~%30 daha hızlı.
- llama.cpp — Düşük seviye C++ runtime; embedded cihazlarda (Raspberry Pi 5, Jetson Orin Nano) Phi-4 Mini’yi koşturmak için kullanılıyor.
Akıllı saatler bile yaklaşıyor: Watch S11 (söylentilere göre) 1B’lik on-device modeliyle 2026 sonunda gelebilir. SLM ölçeği aşağı doğru iniyor, görev tarafı genişliyor.
SLM Kullanım Senaryoları: Ne İçin Gerçekten İyi?
Tatlı nokta listesi (her birinde SLM, LLM’den daha ekonomik veya daha gizli):
- Veri çıkarımı — Faturadan tarih, miktar, satıcı bilgisini çekmek. Phi-4 Mini hızı + doğruluğu cloud LLM’le birebir.
- Sınıflandırma — Müşteri e-postasını “şikayet/satış/teknik destek” diye etiketlemek. Qwen 3 4B saniyede 1000 etiket.
- Özetleme — Toplantı transkriptini 5 maddelik özete indirgemek. Gemma 3 12B en doğal Türkçe özeti çıkarıyor.
- Kod tamamlama — Lokal IDE’de hızlı autocomplete. Phi-4 14B Cursor/Continue eklentilerinde GPT-3.5 yerine kullanılabilir.
- Çeviri — Kısa metin (1 sayfa altı) İngilizce-Türkçe. Qwen 3 8B, DeepL kalitesine yaklaşıyor.
- NER (Named Entity Recognition) — Metinden kişi/yer/şirket adı çıkarma. Eğitim ücretsiz, çıkarım anlık.
- Chatbot — dar alan — “Ürünümüzün iade politikası nedir?” gibi 30 sınırlı soruyu cevaplayan asistan. SLM mükemmel.
- Voice assistant — Yerel sesli asistan (Whisper + SLM + TTS); Alexa/Google Home’un gizliliğe duyarlı alternatifi.
Tersi: Yaratıcı yazım, uzun romanlar, karmaşık matematik kanıtları, çok dilli uzun bağlam → LLM’in işi. Modeli görevle eşleştirmek SLM çağının en önemli mühendislik becerisi.
Sıkça Sorulan Sorular (FAQ)
Phi-4 yerel kullanımı için minimum donanım nedir?
Phi-4 Mini (3.8B) için 8 GB RAM yeterli — entegre GPU veya CPU üzerinde rahat çalışır. Phi-4 (14B) için 16 GB RAM önerilir; 4-bit quantize edildiğinde ~8.4 GB bellek tutar. Apple Silicon Mac kullanıyorsanız (M1/M2/M3/M4) avantajlısınız: unified memory mimarisi sayesinde sistem RAM’iniz doğrudan GPU belleği gibi kullanılıyor.
SLM ne kadar doğru, GPT-4’e ne kadar yakın?
Görev türüne göre değişir. Akıl yürütme ve kod (HumanEval): Phi-4 (14B) %82.6’da, GPT-4’ün %85.4’üne 3 puan mesafede. MMLU-Pro genel bilgi: Qwen 3 8B %72.4 ile GPT-3.5 seviyesini geçiyor. Yaratıcı yazım veya uzun bağlam: aralık 10-20 puan açılır. Hedefiniz dar görev (sınıflandırma, çıkarım) ise SLM’nin GPT-4’ten ayırt edilemeyecek kadar yakın olduğunu göreceksiniz.
Phi-4 vs Gemma 3 vs Qwen 3: Bir cümleyle?
Phi-4 mantık ve kodda lider; Gemma 3 denge ve Google ekosisteminde rahat; Qwen 3 Türkçede en akıcı. Üçü de tek bilgisayarda yan yana indirilebilir ve gün içinde role göre değiştirilebilir. Çoğu power user üçünü de yüklü tutar.
SLM’ler internetsiz tamamen çalışır mı?
Evet — ağırlık dosyaları bir kez indirildikten sonra hiçbir ağ trafiği üretmezler. Uçakta, dağda, Faraday kafesinde — fark etmez. Ollama çalışırken hiçbir bağlantı kurmaz; bunu Little Snitch (macOS) veya nethogs (Linux) ile kanıtlayabilirsiniz.
SLM ile fine-tuning yapabilir miyim?
Evet ve çok daha ucuz. 4B’lik bir modeli LoRA (Low-Rank Adaptation) ile kendi verinize fine-tune etmek 8 GB RAM + 1 RTX 3060 (12 GB VRAM) ile yapılabilir; tipik bir alan adaptasyonu 2-6 saat sürer. GPT-4 fine-tune etmek için OpenAI’ya gidip ödeme yapmak zorundasınız; SLM tarafında kendi makineniz ve birkaç bin satırlık eğitim verisi yeterli. Llama ailesinin tekniklerinden bu konuda öğreneceğiniz çok şey var.
Türkçe için en iyi SLM hangisi?
2026 itibarıyla Qwen 3 8B. Alibaba’nın çok dilli odaklı eğitim verisi Türkçe gramerini, deyim hassasiyetini ve teknik terim çevirisini Phi-4’ten net önde tutuyor. Gemma 3 ikinci sırada; Phi-4 üçüncü. Eğer cihazınız 8B’yi taşıyamıyorsa Qwen 3 4B hâlâ Türkçede Gemma 4B’den iyi.
Tek bir SLM yetmezse ne yaparım?
Modelleri görev için zincirleyin (model routing). Basit istekler için Qwen 3 4B, kod için Phi-4, çeviri için Qwen 3 8B — bir orchestrator tüm istekleri uygun modele yönlendirir. Bu mimari “küçük model federasyonu” 2026’nın hızla yayılan deseni; tek devasa LLM’den daha esnek ve ucuz.
Sonuç: Küçük Olan Yeni Büyük
2025’in başında SLM “akademik merak konusu”ydu. 2026 ortasında bir tablet bilgisayarda Phi-4 Mini açıp İngilizce-Türkçe sözlük tartışması yapmak, kod tamamlatmak, e-postaları sınıflandırmak normalleşti. Ekosistemin yönü açık: modeller her ay küçülüyor, görevler her ay genişliyor.
Pratik öneri — bu hafta yapın:
- Ollama yüklüyse
ollama run qwen3:4bile başlayın. Türkçeye en uygun giriş. - 5 saatlik kullanım sonrası iki modeli daha indirin: Phi-4 Mini (kod) ve Gemma 3 4B (denge).
- Bir hafta sonunda hangi göreviniz hangi modeli istiyor, kendiniz haritalandırın.
- Bu yığınla ChatGPT abonenliğinin %70’ini ikame ettiğinizi göreceksiniz.
Edge AI, on-device privacy, çevrimdışı dayanıklılık — üçü de SLM’nin sıkı bağlamlarında zaten gerçeği. 2026’nın geri kalanında “bunu cihazda halledebilir miyiz?” sorusu her yapay zeka projesinin ilk gündem maddesi olacak. Ve cevap, giderek daha sık, “evet”.
Daha fazla pratik AI rehberi, model incelemesi ve haftalık ekosistem özetleri için yapayzekasozluk.tr/blog sayfasını takipte tutun.