ChatGPT ya da Claude’a bir şey sordunuz ve aldığınız yanıt beklentinizin çok altında kaldı. Aynı soruyu farklı kelimelerle yeniden yazdınız, bu sefer model tam istediğinizi verdi. Model değişmemişti, veri de değişmemişti. Değişen tek şey cümlenizin yapısıydı.
Bu farkı anlayıp kasıtlı biçimde yönetme pratiğine prompt engineering deniyor. Bir yapay zeka modelinin çıktı kalitesi büyük ölçüde girdinin nasıl kurulduğuna bağlıdır. Prompt engineering bunu bir sezgi meselesinden çıkarıp öğrenilebilir bir mühendislik disiplinine dönüştürür. Model aptal değil — sadece yanlış yönlendirilmiş olabilir.

Prompt engineering nedir?
Prompt engineering, bir dil modeline verilen girdileri belirli bir amaca yönelik sonuçlar alacak şekilde tasarlama pratiğidir. Teknik açıdan bakıldığında, modelin ağırlıklarını değiştirmeden onun davranışını şekillendirmenin en doğrudan yoludur.
Kavram, 2020’de OpenAI’ın GPT-3’ü kamuya açmasıyla araştırmacıların gündemine girdi. Kısa süre sonra modele verilen birkaç örneğin çıktı kalitesini ciddi biçimde artırdığı fark edildi. 2022’de InstructGPT’nin ardından kullanıcı talimatlarına hassas yanıt veren modeller yaygınlaşınca iyi bir prompt yazmak gerçek bir beceri hâline geldi. Günümüzde büyük teknoloji şirketleri “prompt engineer” unvanıyla çalışan mühendisler istihdam ediyor.
Bu disiplinin önemi üç somut nedene dayanıyor: maliyet, güvenilirlik ve ölçeklenebilirlik.
Dil modelleri işledikleri token başına maliyet üretir. Belirsiz ya da gereksiz uzun bir prompt hem pahalı hem verimsizdir. Bunun ötesinde, bir sistemi üretim ortamında kullanıyorsanız aynı promptun her seferinde tutarlı format ve içerikte yanıt vermesi gerekir; bunun tek garantisi yapılandırılmış bir prompt tasarımıdır. En önemlisi, iyi yazılmış promptlarla küçük modeller büyük çıktılar üretebilir. GPT-4o veya Claude Opus gibi güçlü ama pahalı seçeneklere her istek atmak zorunda kalmazsınız. “Garbage in, garbage out” prensibi burada da geçerlidir: model ne kadar iyi olursa olsun, kirli girdi kirli çıktı doğurur.
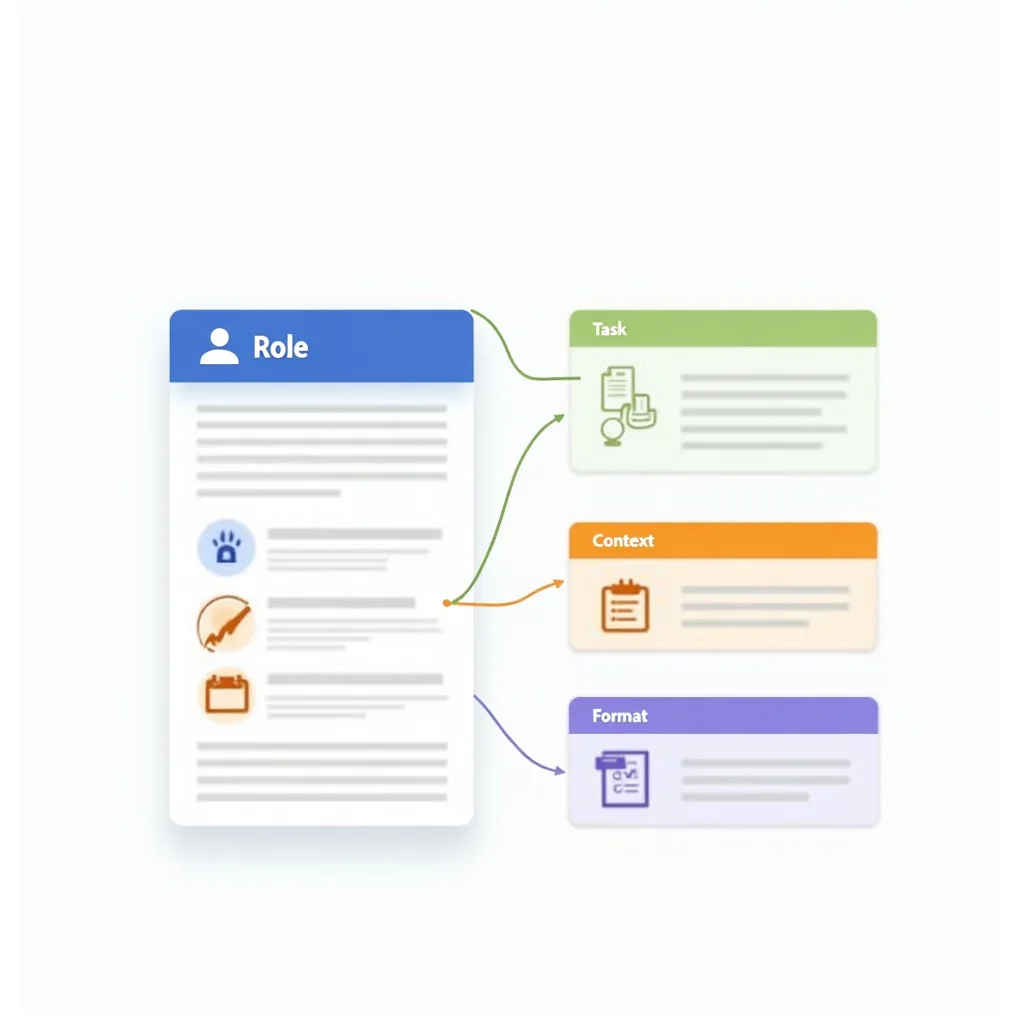
Temel prompt anatomisi
İyi bir prompt birkaç farklı katmandan oluşur.
Role (Persona): Modele ne olduğunu söyler. “Sen deneyimli bir hukuk danışmanısın” ya da “Bir Python kod inceleyicisi olarak hareket et” şeklinde başlayan bir sistem mesajı, modelin tüm yanıtlarını o çerçeveye oturtmasını sağlar.
Görev / Talimat: Modelin yapmasını istediğiniz şeyi açık, eylem odaklı bir cümleyle ifade eder. “Şu metni özetle” yerine “Aşağıdaki metinden üç maddelik bir yönetici özeti çıkar, her madde en fazla iki cümle olsun” demek çok daha net bir yönlendirmedir.
Bağlam / Veri: Modele arka plan bilgisi ya da çalışacağı ham veriyi verir. Bağlam ne kadar zengin olursa yanıt o kadar isabetli olur. Boş bir şablon yerine gerçek içerik veya parametreler sunmak modelin tahmin yükünü azaltır.
Format talebi: Yanıtın nasıl görünmesini istediğinizi belirtir: JSON, madde listesi, tablo, belirli bir başlık yapısı gibi. Bu katmanı atlamak modelin formatı kendi yorumuyla doldurmasına yol açar; bu da çoğunlukla beklenmedik bir çıktı demektir.
Kısıtlamalar: Modelin yapmaması ya da öncelik vermemesi gereken durumları tanımlar. Uzunluk sınırı, kullanılacak dil, ton veya belirli bir terminoloji standardı buraya girer.
Zero-shot, one-shot, few-shot prompting
Bu üçlü, GPT-3 araştırmacılarının orijinal terminolojisinden geliyor ve bugün hâlâ en temel sınıflandırma olarak kullanılıyor.
Zero-shot prompting, modele hiçbir örnek vermeden doğrudan görevi tanımlamaktır. Model önceki eğitiminden edindiği bilgiyi kullanarak yanıt üretir.
Aşağıdaki müşteri yorumunun duygusunu belirle: olumlu, olumsuz veya nötr.
Yorum: "Ürün güzeldi ama kargo bir haftadan uzun sürdü."One-shot prompting, göreve başlamadan önce modele tek bir örnek sunar. Modelin beklenen çıktı formatını önceki eğitiminden değil, doğrudan sizden öğrenmesini sağlar.
Few-shot prompting ise 2-5 arası örnek içerir. Özellikle hassas çıktı formatları, az bilinen alanlar veya özel bir yazı tonu gerektiğinde etkisini gösterir.
Aşağıdaki yorumları sınıflandır:
Yorum: "Ürün mükemmeldi, çok beğendim." → Olumlu
Yorum: "Paket hasar görmüş geldi." → Olumsuz
Yorum: "Fiyatına göre idare eder." → Nötr
Yorum: "Renk biraz farklıydı ama işlevsel."Wei ve arkadaşlarının 2022 GPT-3 çalışmasına göre few-shot promptlar zero-shot yaklaşıma kıyasla %20-40 daha tutarlı çıktı veriyor; bu fark özellikle sınıflandırma ve bilgi çıkarma görevlerinde belirgin.
Chain-of-Thought (CoT) prompting
Chain-of-thought prompting, modeli sonuca atlamak yerine ara adımları yazılı olarak geçirmeye yönlendirir. Yöntemin en bilinen formu “Let’s think step by step” ifadesini prompta eklemektir. Türkçe’de “Adım adım ilerleyerek yanıtla” ya da “Çözüm aşamalarını göster” biçiminde kullanılabilir.
Neden işe yarıyor? Dil modelleri bir sonraki tokeni tahmin ederek çalışır. Modeli ara düşünce adımlarını dışa vurmasına teşvik etmek, onu daha doğru bir yanıta sürükleyen bir zincir oluşturur. Matematik, mantık ve çok adımlı karar problemlerinde bu fark somut biçimde görünür.
Wei ve arkadaşlarının 2022 makalesi, CoT’nin matematiksel akıl yürütme testlerinde standart prompting karşısında %40’a varan doğruluk artışı sağladığını gösterdi. O tarihten bu yana yöntem, otomatik kod üretiminden hukuki belge analizine kadar çok daha geniş bir alana uygulandı. Temel sezgi değişmedi: model düşünce sürecini yazarken kendi çıktısına “bakarak” bir sonraki tahmini kalibre eder, bu da özellikle çok adımlı zincirler için önemli bir fark yaratır.
Zero-shot CoT kullanım örneği:
Bir mağazada elmaların kilosu 15 TL, armutların kilosu 20 TL.
Ali 2 kg elma ve 1.5 kg armut aldı. Toplamda ne kadar ödedi?
Adım adım hesapla.Few-shot CoT ise modele yalnızca cevap değil, gerekçeyi de gösteren örnekler sunar; böylece model benzer problemlerde aynı akıl yürütme biçimini taklit eder.
2025 sonu itibarıyla o3, DeepSeek R1 gibi “reasoning modelleri” CoT’yi doğrudan eğitimlerine gömdü. Bu modeller prompt içinde “adım adım düşün” demesek bile dahili bir zincir yürütüyor. Genel amaçlı modellerde ise CoT yönlendirmesi hâlâ anlamlı bir kalite artışı veriyor.
Rol / persona prompting
Modele bir kimlik atamak, onun yanıtları yorumlama ve üretme biçimini kökten değiştirir. Bunun nedeni sihir değil, eğitim verisinin yapısıdır. “Sen deneyimli bir yazılım mimarısın” dediğinizde model, eğitim sırasında emdiği yazılım mimarisi yazılarının tonal kalıplarını ve terminolojisini ön plana çıkarır.
Kullanım açısından iki katman var: sistem promptu ve kullanıcı promptu. Sistem promptu, konuşmanın tamamına uygulanan kalıcı talimat katmanıdır. API kullanıcıları bunu doğrudan kontrol edebilir; ChatGPT gibi arayüzlerde ise sistem mesajı platforma gömülüdür ya da “Custom Instructions” gibi özelliklerle ayarlanabilir.
İki yaygın tuzağa dikkat etmek gerekir. Birincisi, sycophancy (dalkavukluk) riski: güçlü bir persona atadığınızda model bazen kullanıcının beklentisine uygun yanıt verme eğilimine girer ve gerçeği değil, beklentiyi doğrulayan çıktılar üretebilir. Doğrulama ya da hata ayıklama görevlerinde eleştirel bir persona (“beni yanıltmayan bir kod inceleyicisi”) seçmek daha güvenlidir. İkinci tuzak aşırı kısıtlanmadır: çok katı bir persona modeli köşeye sıkıştırabilir. “Yalnızca evet/hayır cevap ver” gibi kısıtlamalar cevabın nüansını silip hatalı yönlendirmeye yol açar.
İleri teknikler: ReAct, Tree-of-Thought, Self-Consistency
Bu teknikler basit sohbet uygulamalarından ziyade çok adımlı ya da yüksek doğruluk gerektiren sistemlerde ortaya çıktı.
ReAct (Reason + Act), modeli hem akıl yürütmeye hem de araç kullanmaya yönlendiren bir çerçevedir. Her adımda model düşünce adımını yazar, bir eylem gerçekleştirir (web araması, kod çalıştırma, API çağrısı), ardından gözlemi bir sonraki adıma taşır. Yapay zeka ajanlık sistemlerinde bugün yaygın kullanılan temel mimari budur.
Tree-of-Thought (ToT), modelin birden fazla çözüm yolunu paralel olarak keşfetmesini ve her dalı değerlendirmesini sağlar. Tek doğru cevabın olmadığı ya da araştırma gerektiren problemlerde standart CoT’den belirgin biçimde üstündür; ancak maliyet de buna paralel yükselir.
Self-Consistency, aynı promptu birden fazla kez çalıştırıp en sık tekrar eden çıktıyı gerçek yanıt olarak almaktır. Oy çokluğu mantığıyla çalışır. Kritik kararlar, tıbbi bilgi özeti ya da hukuki belge analizi gibi alanlarda tek çalıştırmaya güvenmekten daha güvenilir sonuçlar verir.
ReAct ve ToT çok adımlı ajanlar ve araştırma görevleri için uygundur. Self-Consistency ise gecikmesi tolere edilebilir, doğruluk kritik sistemlerde işe yarar. Başlangıç seviyesindeki kullanımlar için bu üçüne gerek yoktur; CoT ve few-shot büyük çoğunluğu karşılar.
Kaçınılması gereken yaygın hatalar
Belirsiz talimat. “Güzel bir metin yaz” modelini çıkmaza sokar. Model “güzel”in ne anlama geldiğini bilmez. Bunun yerine: “300 kelimelik, resmi olmayan ama bilgilendirici tonlu, birinci kişi kullanılmayan bir ürün açıklaması yaz.”
Negatif talimat tuzağı. “Jargon kullanma” yerine “sade, kısa cümleler kur ve teknik terimleri ilk geçişte tanımla” demek çok daha iyi çalışır. Modeller yasaklama talimatlarına pozitif yönlendirmeler kadar iyi uymaz.
Prompt injection zafiyeti. Kullanıcıdan gelen metni doğrudan sistem promptuna ya da kritik talimatlara eklerseniz, kötü niyetli girdi talimatlarınızın üzerine yazabilir. Üretim sistemlerinde kullanıcı girdisini sistem talimatlarından net biçimde ayırın.
Over-prompting. Çok sayıda kısıtlama, persona ve format talebi aynı anda verildiğinde model bunların arasında kalmaya çalışır ve çoğunu görmezden gelir. Bir promptta üçten fazla aktif kısıtlama varsa basitleştirmeyi ya da görevi alt görevlere bölmeyi düşünün.
Model farklılıkları: GPT, Claude, Gemini
Her modelin bir “dili” var. Bu, eğitim verisi ve ince ayar süreçlerinin yarattığı bir önyargıdır; iyi prompt yazarları bu farklılıkları tanır.
GPT (OpenAI): Talimat takibinde genellikle güçlüdür. Çok doğal dil tonuna iyi yanıt verir; aşırı resmi ya da teknik bir sistem promptu bazen metnin akışını sertleştirir.
Claude (Anthropic): XML etiketleriyle yapılandırılmış promptlara özellikle iyi yanıt verir. <instructions>, <context>, <examples> etiketleri içeriği net biçimde böldüğünden Claude bu yapıyı takip etmekte başarılıdır. Uzun belgeler ve çok adımlı görevler için geniş bağlam penceresini aktif kullanmak gerekir.
Gemini (Google): Metin ile görüntüyü birlikte işleyebildiği için karma prompt tasarımlarında öne çıkar. Kod üretim ve analiz görevlerinde yapılandırılmış talimatlara iyi yanıt verir.

Modeller arasında taşınabilir bir prompt tasarımı istiyorsanız aşırı modele özgü sözdiziminden kaçının. Açık talimatlar, net format talepleri ve iyi kurulmuş bağlam her modelde işe yarar. Pratik bir kural olarak: bir promptu farklı bir modele taşıdığınızda yalnızca küçük dokunuşlar gerektiriyorsa doğru yazılmış demektir. Büyük ölçekli yeniden yazma gerektiriyorsa, büyük ihtimalle modele özgü örtük davranışlara fazla yaslandınız.
5 hazır prompt şablonu
1. Blog makalesi yazma
Sen SEO odaklı bir içerik yazarısın.
Görev: [KONU] hakkında Türkçe blog makalesi yaz.
Uzunluk: 800-1000 kelime.
Hedef kitle: Konuya yeni başlayan okuyucular.
Format: H2 başlıklar kullan, her bölüm 2-3 paragraf, teknik terimler ilk geçişte tanımlanmalı.
Ton: Bilgilendirici ama sohbet dili.
Anahtar kelime: [ANAHTAR_KELİME] — başlıkta ve ilk paragrafta geçmeli.2. Kod hata ayıklama
Sen kıdemli bir Python geliştiricisisin.
Aşağıdaki kodu incele ve şunları döndür:
1. Hatanın tam nedeni (bir cümle)
2. Düzeltilmiş kod bloğu
3. Bu hatayı önleyecek bir iyileştirme önerisi
Kod:
```python
[KOD_BURAYA]
### 3. Toplantı notu özetleme
Aşağıdaki ham toplantı notunu oku ve şu çıktıyı üret:
- 3 maddelik özet (her madde max 1 cümle)
- Alınan kararlar listesi
- Sonraki adımlar ve sorumlu kişiler (varsa)
Ham not: [HAM_NOT]
### 4. E-posta taslağı
Görev: Profesyonel bir iş e-postası yaz. Alıcı: [Alıcı rolü, ör. “potansiyel müşteri”] Amaç: [ör. “ilk teklif sunumu için toplantı talebi”] Ton: Resmi ama sıcak. Uzunluk: 150 kelimeden kısa. Kişisel bilgiler: Gönderen [İSİM], [ŞİRKET].
### 5. Veri analizi yorumlama
Sen bir veri analisti olarak hareket et. Aşağıdaki veriyi analiz et ve şunları döndür:
- Öne çıkan 3 gözlem
- Dikkat çeken anomali ya da istisna (varsa)
- Bu veriye dayanarak yapılabilecek iki öneri
Veri: [VERİ]
## Başlangıç için yeterli, derinleşmek için yetersiz
Prompt engineering, modelin ağırlıklarına dokunmadan onun kapasitesini farklı biçimlerde kullanmanın en pratik yoludur. Öğrenme eğrisi de nispeten düzgündür: birkaç temel ilkeyi içselleştirdikten sonra net talimat yapısı, uygun örnekler ve düşünce zinciri yönlendirmesi büyük çoğunluğu karşılar. Daha karmaşık sistemlerde ReAct veya ToT gerekebilir; ama çoğu proje için bu teknikler gereksiz yük getirir, basit başlamak daha iyidir.
Bir sonraki adım, modelin bağlamını nasıl yönettiğini anlamaktır. Özellikle RAG sistemleri ve uzun belgelerle çalışıyorsanız [context engineering](/blog/context-engineering-nedir-llm-baglamini-tasarlamak/) kritik bir katman ekler. [RAG mimarisi](/blog/rag-nedir-retrieval-augmented-generation-aciklamasi/) ve [AI ajan yapımı](/blog/sifirdan-ai-agent-yapimi/) konuları da buradan devam eder; prompt engineering bu altyapıların temel taşıdır.