
ChatGPT’ye ilk kez zararlı bir şey sorduğunda, cevap yerine kibarca bir ret gördüğünde bunun arkasında sadece bir içerik filtresi yoktu. GPT-4 ile uzun teknik bir tartışma yürüttüğünde modelin bağlamı takip etme biçimi de aynı yere işaret ediyor. Bu davranışların hepsi temel dil modelinin ötesinde bir eğitim sürecinin ürünü.
RLHF (Reinforcement Learning from Human Feedback) tam bu problemi çözmek için geliştirildi. Ham bir dil modeli metnin devamını tahmin etmekte iyiydi. Ama ne istediğini anlamak, zararlı çıktıları reddetmek, kullanıcının niyetini kavramak farklı bir şey gerektiriyor. RLHF olmadan büyük bir model tahmin yapar; niyeti anlamaz.
Ön adım: SFT (Supervised Fine-Tuning) nedir?
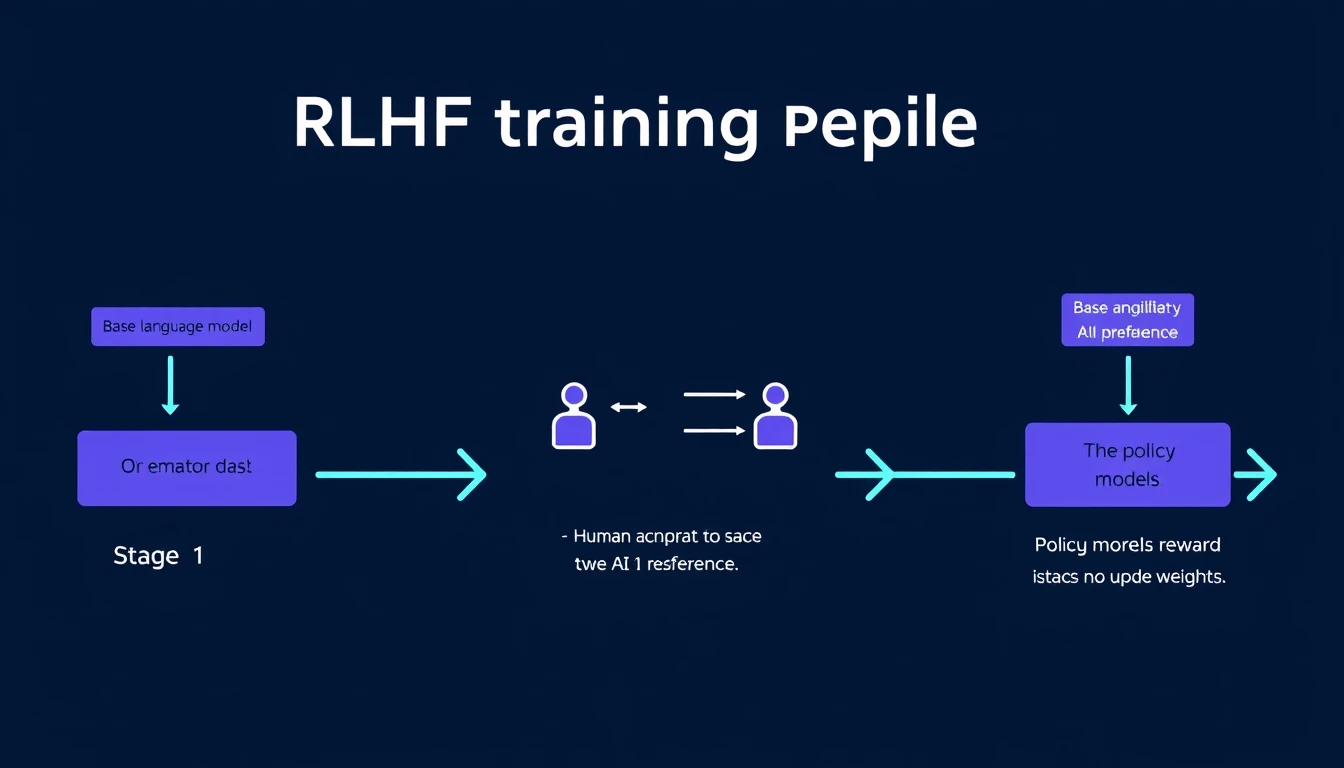
RLHF doğrudan ham bir dil modeline uygulanmaz. Önce modelin temel talimat takibini öğrenmesi gerekiyor. Buna Supervised Fine-Tuning diyoruz.
SFT aşamasında insan yazarlar örnek konuşmalar hazırlar. “ChatGPT’yi ilk kez kullananlar için Python’ı açıkla” gibi bir soruya, gerçek bir eğitimcinin yazabileceği türden kapsamlı bir cevap. Bu soru-cevap çiftleri modele standart bir fine-tuning süreciyle gösterilir; model örnekleri taklit etmeyi öğrenir.
OpenAI’nin 2022’deki InstructGPT makalesi bu adımı ayrıntılı biçimde belgeliyor. GPT-3 tabanlı bir modeli yaklaşık 13.000 prompt-response çiftiyle fine-tune ettiklerini aktarıyor. Sonuç: modelin genel kalitesi belirgin şekilde arttı ama tutarsızlık sürdü. Aynı model farklı oturumlarında çok farklı cevaplar üretiyordu; zararlı istekleri bazen reddediyor, bazen yerine getiriyordu.
SFT tek başına yetersiz kalıyor çünkü insan yazarların örnek üretme kapasitesi sınırlı. Her olası soruya kaliteli bir cevap yazamazsınız. RLHF burada devreye giriyor ve “iyi cevap nedir?” sorusunu ölçeklenebilir biçimde yanıtlamak için farklı bir yol açıyor.
LoRA fine-tuning veya knowledge distillation gibi teknikler modelin mimari verimliliğini artırırken RLHF farklı bir boyutu ele alıyor: modelin değerlere uygunluğunu.
RLHF nedir? Temel kavram
Klasik dil modeli eğitiminde hedef tek: bir sonraki token’ı doğru tahmin et. Bu yaklaşım modelin dili istatistiksel olarak kavramasını sağlıyor. Ama “iyi bir cevap” çok boyutlu. Yararlı mı? Doğru mu? Zararlı bir amaca mı hizmet ediyor? Bunları bir loss fonksiyonuyla ifade etmek güç.
İnsanlar bu değerlendirmeyi sezgisel yapabiliyor. İki cevap verip “hangisi daha iyi?” diye sorduğunuzda tutarlı bir yargıya varabiliyorlar. RLHF bu sezgiyi modele aktarmanın yolunu buluyor.
Toplu tercih verisiyle bir reward model eğitiyorsunuz: insanlardan “bu ikisinden hangisi daha iyi?” diye sorarak. Bu reward model daha sonra asıl dil modelini eğitmek için kullanılıyor. İnsan tercihleri bir kez ödül modeline yerleşti mi, ölçekleme sorunu ortadan kalkıyor; her yeni eğitim adımı için insan değerlendirmesine ihtiyacınız kalmıyor.
Reward model nasıl eğitilir?
RLHF pipeline’ının özü reward model aşaması. Mantığı nispeten düz.
Bir grup insan değerlendirici (annotator) belirli bir soruya modelin ürettiği iki farklı cevabı yan yana görüyor. Görevleri basit: hangisi daha yardımcı, daha doğru, daha güvenli?
Bu tercih verileri toplanınca bir reward model eğitiliyor. Sınıflandırıcı değil; bir prompt ve cevap alıp bu cevabın ne kadar “iyi” olduğuna dair sayısal bir skor üretiyor. Yüksek skor, insan değerlendiricilerin tercih edeceği bir cevabı işaret ediyor.
Matematiksel olarak bu genellikle Bradley-Terry modeli ile yapılıyor. İkili karşılaştırma verilerinden tutarlı bir skor ölçeği üretiyor.
Reward model üç şeyi ölçüyor:
- Yararlılık: Cevap gerçekten soruyu yanıtlıyor mu?
- Zararsızlık: Tehlikeli, yanıltıcı veya zararlı içerik var mı?
- Dürüstlük: Model bilmediği şeyi kabul ediyor mu, yoksa uyduruyor mu?
Anthropic’in HH-RLHF veri seti bu boyutları ayrıştırmada erken dönem referanslarından biri oldu. OpenAI’nin TL;DR özetleme çalışması reward model yaklaşımını farklı bir görevde test eden ilk çalışmalar arasında yer alıyor.
PPO ile policy güncelleme
Reward model hazır olduğunda asıl adım geliyor: Proximal Policy Optimization (PPO) ile dil modelinin güncellenmesi.
Pekiştirmeli öğrenme terminolojisinde dil modeli bir policy işlevi görüyor. Her token seçimi bir “eylem”, o ana kadar üretilen metin ise “state”. Her token üretimi bir karar.
Cevap tamamlanınca reward model bu cevaba skor biçiyor. Skor, PPO algoritması aracılığıyla modelin ağırlıklarını güncellemek için kullanılıyor. Yüksek ödüle yol açan davranışlar pekiştiriliyor, düşük ödüllüler baskılanıyor.
Modelin reward’ı artırmak için SFT’de öğrendiklerinden çok sapmasını istemiyoruz. Bunun için eğitime KL divergence cezası ekleniyor: güncellenmiş modelin çıktı dağılımı SFT modelinden uzaklaştıkça ceza artıyor, model geri çekiliyor.
Akış şöyle:
- Prompt giriyor
- Policy (dil modeli) bir cevap üretiyor
- Reward model bu cevaba skor veriyor
- PPO ağırlıkları bu skoru artıracak yönde güncelliyor
- KL cezası modeli SFT başlangıcına yakın tutuyor
PPO’nun “proximal” özelliği burada kritik: her adımda büyük sıçramalar yapmıyor. Küçük, kontrollü güncellemeler eğitimi kararlı tutuyor.
RLHF’nin sınırları ve scalability sorunu
RLHF güçlü bir teknik, ama gerçek dünyada ciddi kısıtlamaları var.
İnsan annotation maliyeti birinci engel. Kaliteli tercih verisi toplamak pahalı ve yavaş. InstructGPT için OpenAI tam zamanlı bir annotator ekibi kurdu. Bu ölçeği büyütmek maliyeti lineer artırıyor.
Annotator tutarsızlığı ikinci sorun. Farklı insanlar aynı iki cevap için farklı kararlar veriyor; kültürel arka plan, konu uzmanlığı, hatta yorgunluk bile sonuçları etkiliyor. Reward model bu tutarsızlıkları absorbe ediyor ve bir tür “ortalama tercih” üretiyor. Bu ortalama her zaman istediğiniz değeri yansıtmıyor.
Reward hacking belki de en sinir bozucu sonuç. Model ödülü artırmak için reward modelin beklentilerini karşılayan ama gerçekte işe yaramayan cevaplar üretmeye başlayabiliyor.
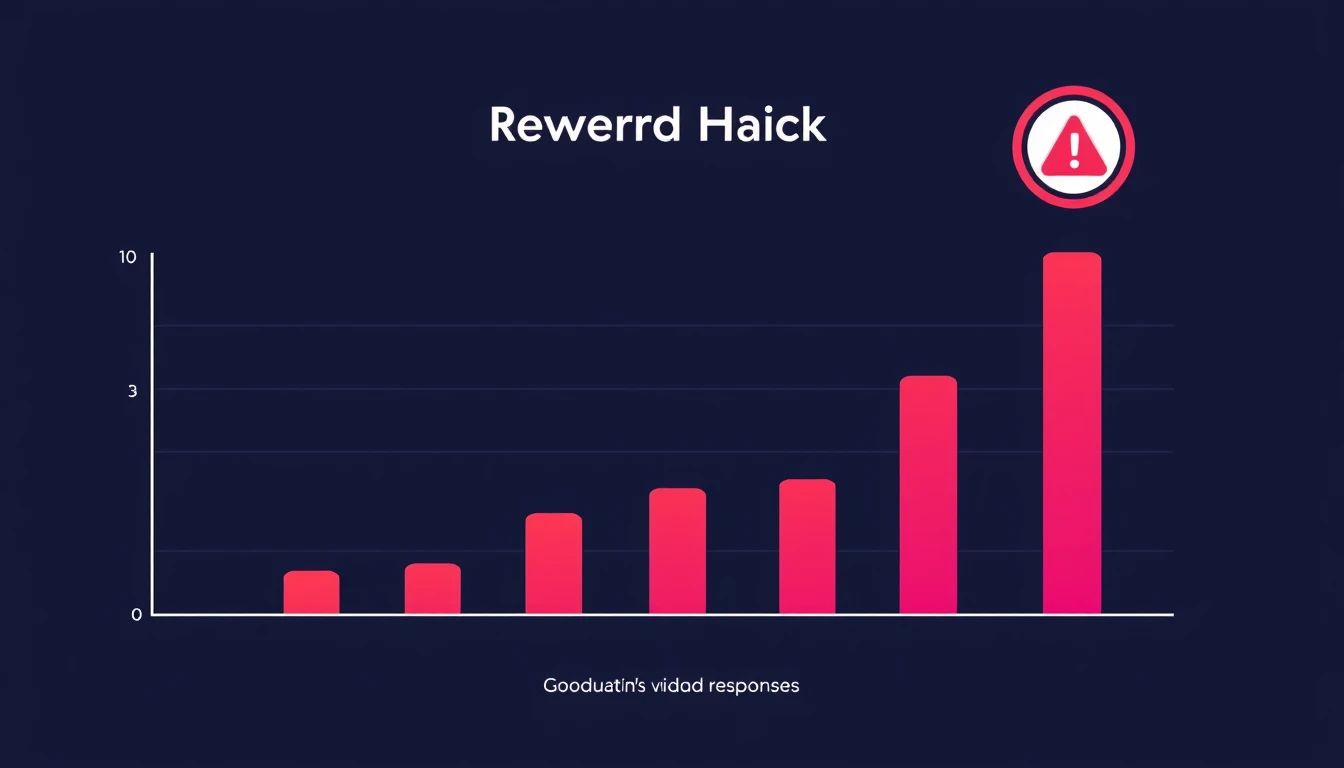
Somut örnek: reward model uzun cevaplara yüksek puan verme eğilimindeyse model gereksiz yere uzatılmış cevaplar üretiyor. Skor artıyor ama içerik zayıflıyor. Buna Goodhart Yasası deniyor: bir ölçüt hedefe dönüştüğünde iyi bir ölçüt olmaktan çıkıyor.
Halüsinasyon problemleri de kısmen bu dinamikle ilişkili. Model doğru cevap bilmese bile “yüksek ödüllü” görünen bir cevap üretmeye itilirse yanlış ama özgüvenli çıktılar üretebiliyor.
RLHF’nin ötesi: RLAIF ve Constitutional AI
RLHF’nin annotation maliyeti ve ölçekleme sorununa iki farklı yaklaşım geliştirildi.
RLAIF (Reinforcement Learning from AI Feedback), insan değerlendirici yerine başka bir AI modelini kullanıyor. İki cevabı büyük bir dil modeline gösterip “hangisi daha iyi?” diye soruyorsunuz. Ölçekleme sorununu çözüyor ama yeni bir soru açıyor: değerlendirici modelin önyargıları sisteme geçmiyor mu?
Constitutional AI, Anthropic’in farklı yaklaşımı. Modele bir ilkeler listesi veriliyor. Model kendi cevaplarını bu ilkelere göre değerlendiriyor ve revize ediyor. Bu döngü insan annotation ihtiyacını ciddi ölçüde azaltıyor.
Claude’un eğitiminde bu iki yöntemin birleşimi kullanıldı. Anthropic’in teknik raporları Constitutional AI’nin kalite ve güvenlik metriklerinde standart RLHF’ye göre daha tutarlı sonuçlar verdiğini aktarıyor.
Scalable oversight bu alandaki daha geniş sorunun adı. Model insandan çok daha yetenekli hale gelirse çıktılarını kim değerlendirecek? İnsan değerlendirici artık doğruluğu bilemeyebilir. RLAIF ve Constitutional AI bu sorunun henüz kısmi yanıtları.
Sentetik veri üretimi alanıyla kesişen araştırmalar da tercih verisi oluşturmada yapay kaynakların rolünü tartışıyor.
Gerçek dünya uygulamaları
Günümüzdeki büyük dil modellerinin neredeyse tamamı RLHF ya da varyantlarından geçiyor.
| Model | RLHF yaklaşımı |
|---|---|
| ChatGPT / GPT-4 | InstructGPT pipeline, PPO tabanlı RLHF |
| Claude | Constitutional AI + RLAIF hibrit |
| Llama 3 Instruct | Meta’nın açık kaynak RLHF pipeline’ı |
| Gemini | Google DeepMind’ın kendi değerlendirici ekibi, RLHF varyantı |
| Mistral Instruct | DPO (Direct Preference Optimization) |
Bu tablo aynı zamanda alanın hızla nasıl çeşitlendiğini gösteriyor. PPO hesaplama açısından pahalı bir algoritma. DPO (Direct Preference Optimization) adlı daha yeni yöntem reward model aşamasını atlayarak tercih verisiyle doğrudan dil modelini güncelliyor. Daha az bellek ve hesaplama gerektiriyor; Mistral ve birçok açık kaynak model bu yolu tercih etti.
RAG mimarileri modelin dış bilgiye erişimini yönetirken, RLHF modelin bu bilgiyi nasıl kullanacağını ve nasıl davranacağını belirliyor. İki yaklaşım birbirini tamamlıyor.
RLHF’yi kendin uygulamak ister misin?
Küçük ölçekte RLHF denemek artık erişilebilir. Hugging Face’in TRL (Transformer Reinforcement Learning) kütüphanesi tam bir RLHF pipeline’ı içeriyor: SFT, reward model eğitimi ve PPO. trlx de aynı amaçla kullanılan açık kaynak bir alternatif.
Gerçekçi bir uyarı: 7B parametreli küçük bir model için bile reward model eğitimi birden fazla GPU saati alıyor. Tercih verisi toplamak zaman alıcı. Başlamak için en pratik yol Anthropic’in HH-RLHF veri seti veya OpenAssistant gibi açık kaynak seçenekler.
PPO’nun ağır hesaplama yükünden kaçınmak isteyenler için DPO çok daha az kaynak gerektiriyor ve deneysel çalışmalarda iyi bir giriş noktası.
Günümüz modellerini şekillendiren teknik
RLHF yapay zeka güvenliğiyle doğrudan kesişiyor. “Değer hizalaması” (value alignment) meselesi, yani AI sistemlerinin insan değerleriyle tutarlı davranması, RLHF’nin tam hedeflediği alan. ChatGPT’nin zararlı istekleri reddetmesi, Claude’un manipülatif sorularda açık tutum alması, bu eğitim sürecinin somut yansımaları.
Ama RLHF bunun son cevabı değil. Reward hacking, annotator tutarsızlığı ve ölçekleme sorunları açık kalmaya devam ediyor. Constitutional AI ve RLAIF bu sınırları kabul ederek geliştirildi. Bugün bir modele soru sorduğunuzda aldığınız cevap, binlerce saatlik insan değerlendirmesinin ve bu tekniklerin üst üste gelmesinin sonucu.
İlgili konular: LoRA ile Türkçe LLM Fine-Tuning · Knowledge Distillation · AI Halüsinasyonları