Transformer Mimarisi Nedir? Encoder-Decoder Rehberi (2026)
Transformer mimarisi, 2017’de Google’ın yayımladığı “Attention is All You Need” makalesiyle ortaya çıktı ve o günden bu yana GPT-4o’dan Gemini 2.0’a kadar neredeyse tüm büyük dil modellerinin temeli oldu. Bu yazıda attention mekanizmasının nasıl çalıştığını, encoder ile decoder bloklarının ne işe yaradığını ve BERT ile GPT’nin neden farklı mimariler kullandığını ele alıyoruz.

Transformer Nedir ve Neden Önemlidir?
RNN ve LSTM’nin sınırları büyüdükçe transformer daha çekici bir alternatif haline geldi. Bugün GPT, BERT, T5, LLaMA ve Mistral bu mimari üzerine kurulu.
RNN ve LSTM’nin Sınırları
RNN’ler metni soldan sağa, kelime kelime işler. İki ciddi sorunu var: uzun bağımlılıkları kaybetme riski (vanishing gradient) ve eğitimde paralelleştirmenin imkansız olması. “Dün akşam aldığım kitabı bugün okumaya başladım” cümlesinde “kitabı” ile “onu” arasındaki ilişkiyi 10 adım geriye taşımak zorunda kalan bir RNN her adımda bilgi kaybeder. LSTM bu sorunu kapılar (gates) ile kısmen çözdü ama büyük ölçekte eğitim yine yavaş kaldı.
”Attention is All You Need”: 2017’de Ne Değişti?
Vaswani ve ekibi recurrence yerine attention kullandı. Attention, bir cümledeki her token’a diğer tüm token’larla aynı anda bakma imkanı tanır. RNN’nin sıralı doğası ortadan kalktı; hem paralelleştirme mümkün oldu hem de 512 token uzaktaki bağımlılıklar ayırt edilebilir hale geldi.
Transformer’ın Modern Yapay Zekadaki Rolü
GPT-4 Turbo, 1.8 trilyon parametresiyle decoder-only transformer bloklarını üst üste yığar. BERT-large ise 24 encoder katmanından oluşur. LLM’lerin tokenizasyon sürecini anlamak için transformer’ın bu temel yapısından başlamak gerekir.
Attention Mekanizması Nasıl Çalışır?
Her token, hangi diğer token’lara dikkat edeceğine karar vermek için üç vektör kullanır: Query (Q), Key (K) ve Value (V).
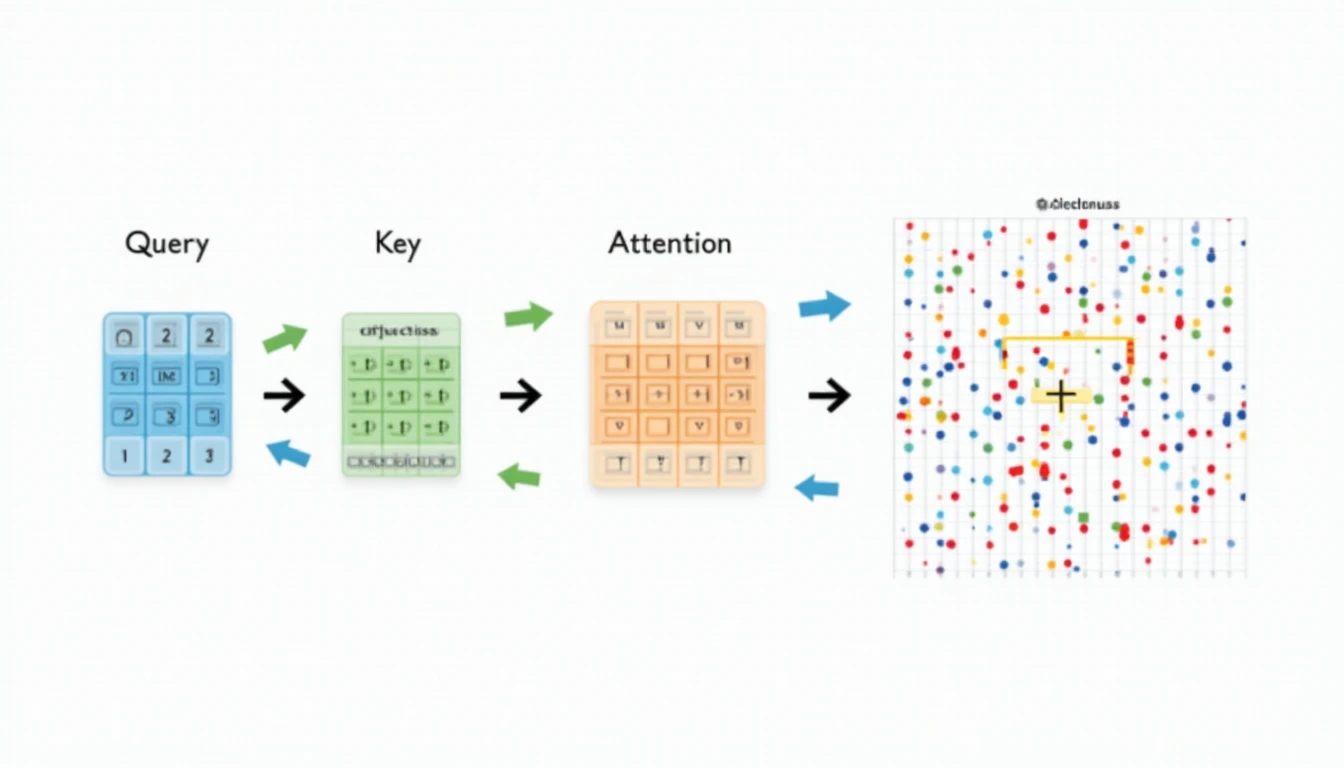
Query, Key, Value: Bilgi Seçim Mantığı
Her token, giriş embedding vektöründen üç matris çarpımıyla Q, K ve V vektörlerine dönüşür. Q “neyi arıyorum?”, K “ben kimim?”, V “içeriğim nedir?” anlamına gelir. Attention skoru şu formülle hesaplanır:
Attention(Q, K, V) = softmax(QKᵀ / √dₖ) · V√dₖ ile bölme, boyut arttıkça patlayan dot product değerlerini normalize eder.
Self-Attention: Kelimeler Arası Bağlam Kurma
Self-attention, Q, K ve V’nin aynı diziden türemesi demektir. “Banka kıyıda mı para kurumunda mı?” cümlesinde self-attention, “banka” token’ının “kıyı” ile olan yakınlığını skora çevirir; yüksek skor “kıyı” anlamını öne çıkarır. Bu işlem hem encoder’da hem decoder’da gerçekleşir.
Multi-Head Attention: Paralel Dikkat Kafaları
Transformer, aynı Q/K/V matrislerini h farklı alt uzaya yansıtır ve her kafayı paralel çalıştırır. BERT-base’de 12 kafa var; her biri farklı sözdizimsel veya anlamsal ilişkiyi öğrenir. Çıktılar birleştirildikten sonra son boyuta yansıtılır.
Pozisyonel Kodlama (Positional Encoding)
Attention, sıra bilgisini görmezden gelir; “kedi fareyi kovaladı” ile “fare kediyi kovaladı” aynı token kümesine sahiptir. Pozisyonel kodlama bu sorunu çözer.
Sıra Bilgisi Neden Şarttır?
Dil sıralamaya bağlıdır. Giriş embedding’lerine pozisyon vektörü eklenmeseydi transformer, bir kelime torbasından (bag of words) farksız kalırdı. Her token’ın pozisyonunu benzersiz bir vektörle kodlamak, modelin sıra bilgisini işleyebilmesini sağlar.
Sinüs/Kosinüs Tabanlı Kodlama
Orijinal makalede pozisyon p ve boyut i için sinüs/kosinüs çifti kullanılır. Bu formülasyon, iki pozisyon arasındaki farkı sabit bir lineer dönüşümle ifade eder; model eğitimde görmediği uzunluktaki dizilere de genelleyebilir.
Modern Alternatifler: RoPE ve ALiBi
LLaMA ve Mistral, sinüs tabanlı kodlama yerine Rotary Position Embedding (RoPE) kullanır. RoPE, relatif pozisyonu doğrudan attention skoruna karıştırır; uzun bağlam pencereleri (128k token) için daha iyi ölçeklenir. ALiBi ise attention matrisine sabit bir ceza terimi ekleyerek eğitim dışı uzunluklara uyum sağlar.
Encoder Mimarisi
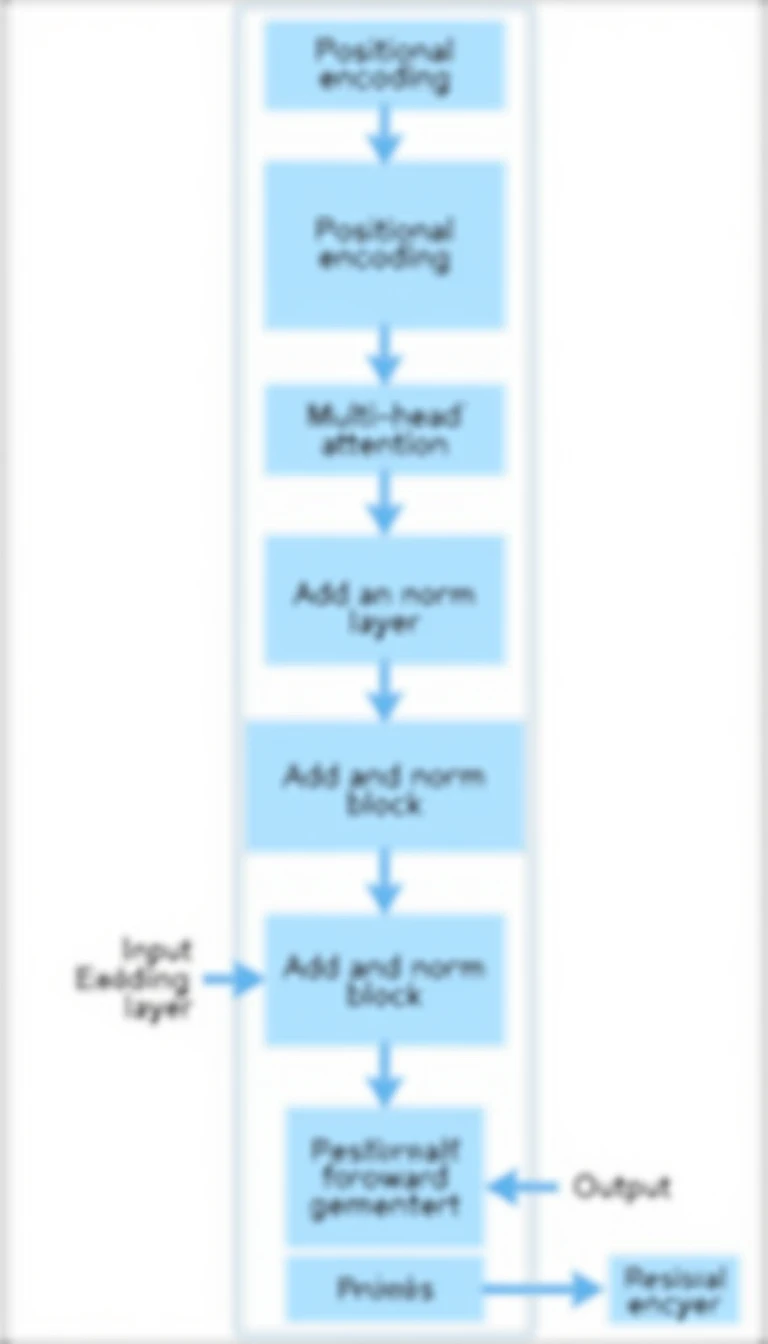
Encoder Katmanının Bileşenleri
Bir encoder katmanı üç bileşenden oluşur:
- Multi-Head Self-Attention: Token’lar arası bağlamı hesaplar.
- Add & Norm: Residual bağlantı artı layer normalization; gradyan akışını stabilize eder.
- Feed-Forward Network (FFN): Token başına bağımsız iki lineer katman; BERT-base’de gizli katman 3.072 boyutludur.
BERT-base bu bloğu 12, BERT-large 24 kez yığar.
BERT: Çift Yönlü Encoder
BERT, maskeli dil modeli (MLM) görevi ile eğitildi: giriş token’larının %15’i [MASK] ile değiştirilir ve model bunları tahmin eder. Self-attention her iki yönde çalıştığı için “çift yönlü” denir; bir token, sağındaki ve solundaki token’ları aynı anda görebilir.
Encoder-Only Modellerin Kullanım Alanları
Encoder modellerinin çıktısı, her token için bir bağlam vektörüdür. Bu yapı metin sınıflandırma, NER, extractive soru cevaplama ve anlamsal benzerlik görevlerine uygundur. BERT-base, RoBERTa, DeBERTa ve DistilBERT bu kategoridedir.
Decoder Mimarisi
Masked Self-Attention Nedir?
Decoder’da self-attention üst üçgen maskesiyle sınırlandırılır. Token t, yalnızca t-1, t-2, … pozisyonlarına bakabilir; ileriki token’lar sıfırlanır. Bu causal masking ile model, bir sonraki token’ı tahmin ederken henüz üretmediği token’ları göremez.
GPT: Autoregressive Decoder
GPT serisi decoder-only transformer kullanır. GPT-2’nin 12 katmanı ve 117M parametresi vardı; GPT-4 Turbo tahminlerine göre 1.8T parametreye ulaştı. Autoregressive üretimde model her adımda tek bir token üretir, bunu bağlam penceresine ekler ve sonraki adımı tahmin eder.
Decoder-Only vs Encoder-Only: Hangi Görev İçin?
Decoder-only modeller serbest metin üretimi için tercih edilir: sohbet, kod yazma, yaratıcı içerik. Encoder-only modeller metin anlama görevlerinde daha verimlidir. GPT-2’yi extractive NER için ince ayar yapmak BERT’e göre daha düşük sonuç verir.
Encoder-Decoder (Seq2Seq) Mimarisi
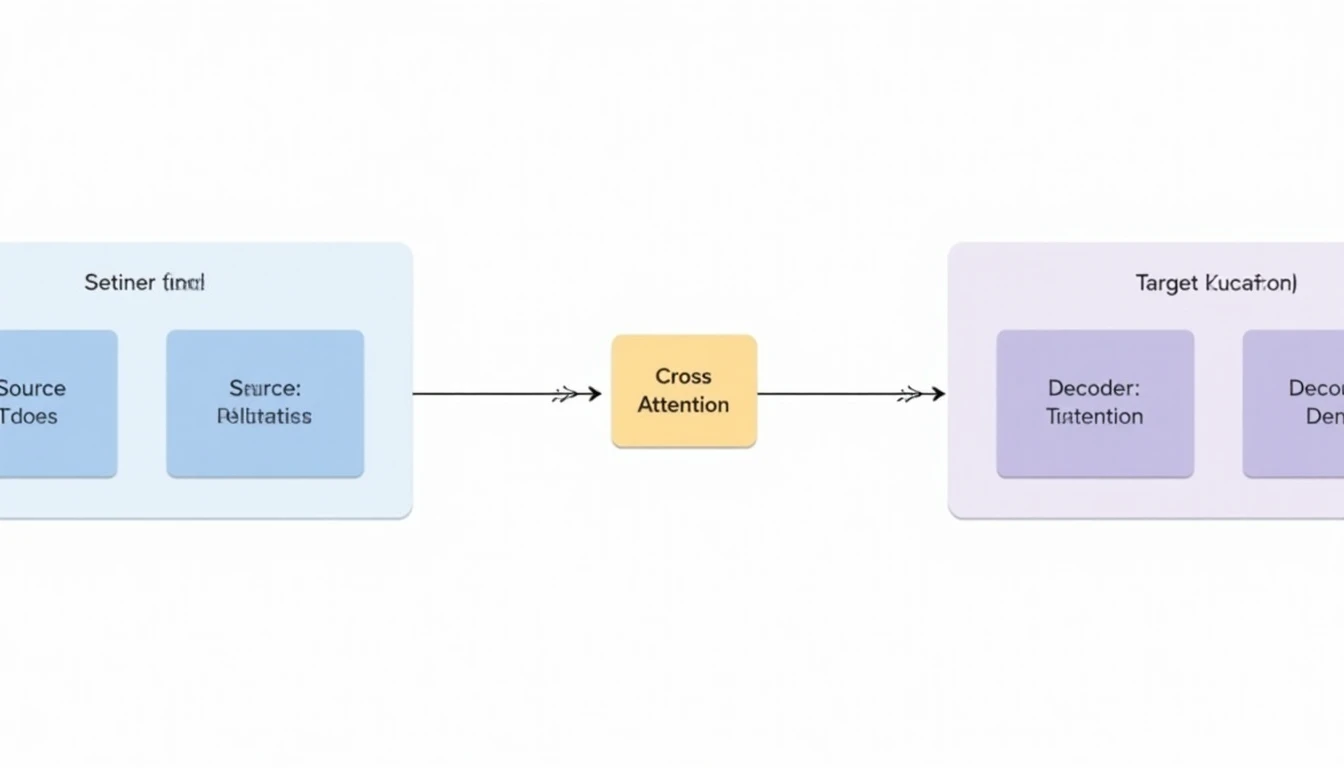
Cross-Attention Mekanizması
Encoder-decoder mimarisinde decoder, encoder çıktısını cross-attention ile okur. Decoder’ın Q’su kendi gizli durumundan, K ve V ise encoder’ın son katman çıktısından türer. Bu yapı decoder’ın kaynak cümlenin tüm bağlamına erişmesini sağlar.
T5 ve BART: Seq2Seq Transformer Örnekleri
T5, her NLP görevini “text-to-text” olarak çerçeveler: çeviri için “translate English to German: …” şeklinde prefix kullanır. BART ise bozulan metni yeniden oluşturma (denoising) ile öneğitim yapar. Her ikisi de encoder-decoder mimarisine dayanır.
Çeviri, Özetleme ve Soru-Cevap Görevleri
Encoder-decoder modeller, kaynak metni dönüştürmeyi gerektiren görevlerde öne çıkar: makine çevirisi, belge özetleme, semantik parsing. MCP ile harici kaynaklara bağlanan agentların bilgi çıkarım aşamasında seq2seq modeller sıklıkla kullanılır.
Hangi Model Hangi Mimariye Dayanır?
Encoder-Only, Decoder-Only, Seq2Seq Karşılaştırması
| Mimari | Örnek Modeller | İdeal Görev |
|---|---|---|
| Encoder-Only | BERT, RoBERTa, DeBERTa | Sınıflandırma, NER, anlama |
| Decoder-Only | GPT-4, LLaMA 3, Mistral | Metin üretimi, kod yazma |
| Encoder-Decoder | T5, BART, mT5 | Çeviri, özetleme, seq2seq |
Parametre Sayısı ve Hesaplama Maliyeti
Attention hesabının karmaşıklığı O(n²); dizi uzunluğu n ile karesel artar. 4.096 token girişinde 16.7M attention çifti hesaplanır. 128k token penceresinde standart attention bellek açısından pratik değildir.
Flash Attention ve MoE ile Ölçeklendirme
Flash Attention (Dao et al., 2022), attention hesabını IO-aware şekilde düzenler; GPU bellek bant genişliğini daha verimli kullanarak hızı artırır. Mixture of Experts (MoE) ise her token için yalnızca belirli FFN uzmanlarını etkinleştirir; parametre sayısını artırmadan hesaplama maliyetini düşürür. Mixtral 8x7B ve GPT-4 bu tekniklere dayanır.
Sık Sorulan Sorular
Transformer ile RNN arasındaki temel fark nedir?
RNN metni soldan sağa sıralı işler ve uzun bağımlılıklarda gradyan kaybı yaşar. Transformer, attention ile tüm token çiftlerini paralel değerlendirir. RNN’e göre çok daha hızlı eğitilir ve 100k token’ı aşan bağlamlarda daha iyi performans gösterir.
BERT mi yoksa GPT mi daha güçlüdür?
Göreve bağlı. BERT, metin sınıflandırma ve anlama görevlerinde GPT ailesinin küçük versiyonlarından daha iyi skor alır. GPT-4 Turbo gibi büyük decoder modelleri ise açık uçlu üretim, mantık yürütme ve kod yazımında BERT’i geride bırakır. Soru “hangi görev için?” olmalıdır.
Attention mekanizması neden bu kadar hesaplama gerektirir?
Attention karmaşıklığı O(n² × d): n token uzunluğu, d model boyutu. n=2.048 için 4.194.304 skaler çarpım hesaplanır. Flash Attention bu matrisi bloklar halinde işleyerek bellek erişimini azaltır; matematiksel karmaşıklık değişmez.
Pozisyonel kodlama olmadan transformer çalışır mı?
Teknik olarak çalışır, ama “kedi fareyi kovaladı” ile “fare kediyi kovaladı” modele özdeş görünür. Attention hesabı sıra bağımsız olduğu için pozisyon bilgisi olmadan dil görevlerinde doğru sonuç alınamaz.
LLM’lerde kaç transformer katmanı kullanılır?
Modele göre değişir: GPT-2 small 12 katman, GPT-2 XL 48 katman, LLaMA 3 8B 32 katman, LLaMA 3 70B 80 katman içerir. Daha fazla katman daha derin soyutlamaya karşılık gelir; parametre sayısı katman derinliği ile gizli boyutun karesiyle orantılı büyür.