list_altİçindekilerexpand_more
- 01Context Engineering Nedir?
- 02Bağlam Penceresinin 5 Katmanı
- 031. Sistem Promptu
- 042. Statik Bellek
- 053. Dinamik Bağlam / RAG
- 064. Araçlar ve Fonksiyon Tanımları
- 075. Konuşma Geçmişi
- 08Temel Tasarım İlkeleri
- 09Relevansi Önce
- 10Token Bütçesi Yönetimi
- 11Hiyerarşi ve Öncelik
- 12Çelişki Yönetimi
- 13Pratik: AI Agent Context Tasarımı
- 14Yaygın Hatalar
- 15Her Şeyi Sistem Promptuna Tıkmak
- 16Statik Bağlamı Dinamik Sanmak
- 17Alakasız RAG Chunk’ları
- 18Şişirilmiş Araç Tanımları
- 19Hata: Konuşma Geçmişini Kesmek
- 20Araçlar ve Frameworkler
- 21Bundan Sonra Ne?
2023’te herkes prompt yazmayı öğrendi. “Act as an expert” ile başla, birkaç örnek ekle, sonuçlar iyileşti. Ama bir noktada bu formüller yetersiz kalmaya başladı. Modeller büyüdükçe, ajanlar karmaşıklaştıkça, tek bir prompta sığmayan bir tasarım problemi ortaya çıktı.
Prompt engineering öldü mü? Hayır. Ama tek başına yetmiyor artık.
2026’da bu boşluğu dolduran terimin adı context engineering. Andrej Karpathy, prompt engineering’i “vibes-based” (his bazlı) diye nitelendirip context engineering’i mühendislik pratiği olarak konumlandırdı. Bu tweet’in ardından kavram teknik çevrelerde hızla yerleşti.
Context Engineering Nedir?
Kısa tanım: Context engineering, bir LLM’in bağlam penceresine neyin, ne zaman, hangi sırayla gireceğini planlı biçimde tasarlama pratiğidir.
Prompt engineering, tek bir mesajı en iyi şekilde yazmaya odaklanır. Context engineering ise tüm oturumu, tüm sistemi tasarlar. Sistem promptundan geçmişe, RAG chunk’larından araç çıktılarına kadar bağlam penceresine dolan her şey bu disiplinin kapsamına girer.
Prompt engineering bir e-posta yazmak gibidir. Context engineering ise o e-postayı kimin alacağını, hangi ekleri göreceğini ve önceki yazışmalardan hangilerinin dahil edileceğini planlamak gibidir.
Karpathy şunu söyledi: “Prompt engineering is vibe-based. Context engineering is the actual craft.” Craft öğrenilebilir ve tekrarlanabilir. Vibes değil.
Pratik anlamda context engineering şu soruları yanıtlar:
- Sistem promptuna ne girmeli, ne çıkmalı?
- Hangi bilgiler dinamik olarak çekilmeli, hangisi statik kalmalı?
- Konuşma geçmişinin kaç turu tutulmalı?
- Araç çıktıları tokena nasıl sıkıştırılmalı?
- Birden fazla ajan arasında bağlam nasıl aktarılmalı?
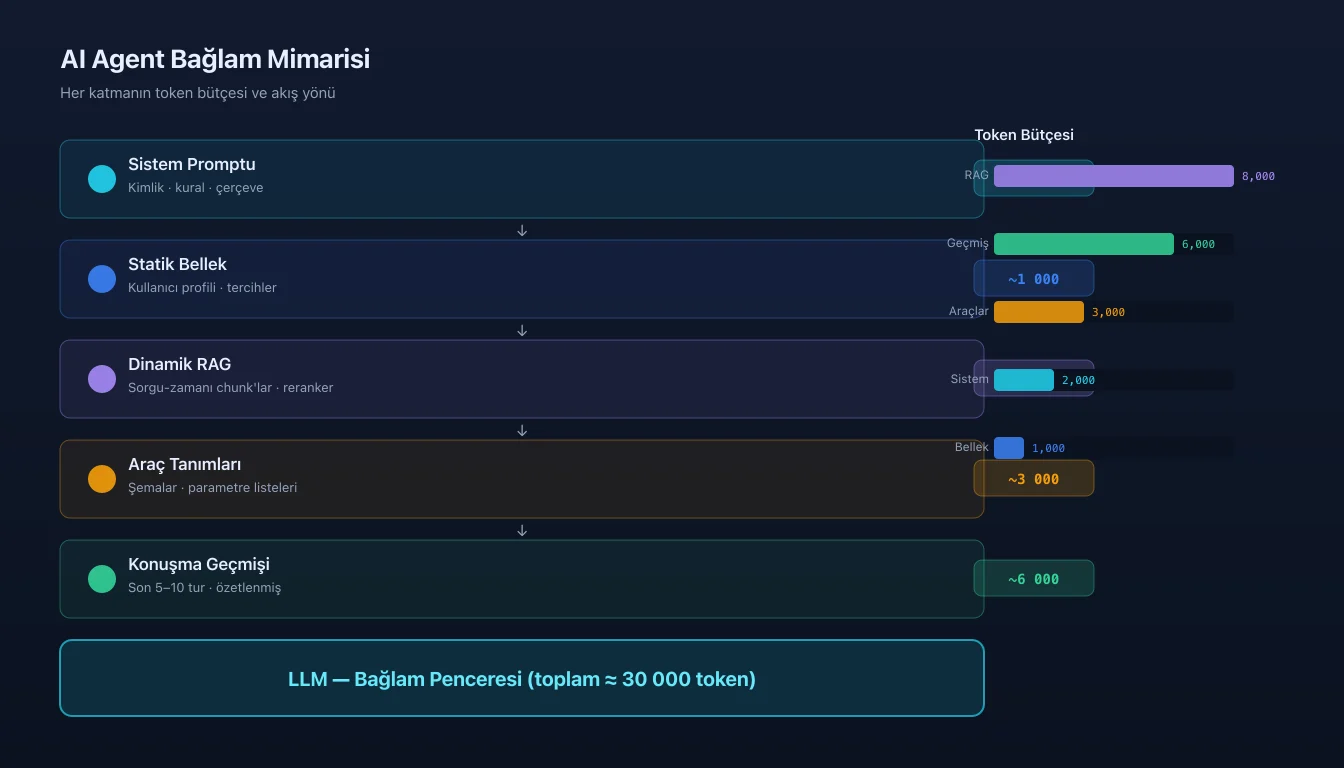
Bağlam Penceresinin 5 Katmanı
LLM’in gördüğü her şey bağlam penceresinde toplanır. Bu pencereyi dolduran kaynaklar beş ana katmana ayrılır.
1. Sistem Promptu
Modele kimliğini, görevini ve kısıtlamalarını tanımlayan kalıcı blok. Değişmez, her turda gönderilir.
system_prompt: |
Sen yapayzekasozluk.tr için Türkçe içerik üreten bir editörsün.
Teknik terimleri önce tanımla, sonra örnekle.
Asla kaynak uydurmaz, belirsizlerde "bilmiyorum" dersin.Sistem promptu ne kadar şişerse modelin işlem alanı o kadar daralır. Kural değil, çerçeve yaz.
2. Statik Bellek
Kullanıcıya özgü, nadiren değişen bilgiler: tercihler, profil, uzun vadeli hedefler. Veritabanından çekilip her oturumda enjekte edilir.
{
"user_context": {
"expertise": "junior developer",
"language": "tr",
"preferred_examples": ["Python", "JavaScript"]
}
}3. Dinamik Bağlam / RAG
Sorguya göre gerçek zamanlı çekilen belgeler. En alakalı chunk’lar embedding benzerliğiyle seçilir, pencereye eklenir.
retrieved_chunks = vector_db.query(
query=user_message,
top_k=5,
filter={"language": "tr"}
)
context += format_chunks(retrieved_chunks)“En yüksek benzerlik skoru” her zaman “en alakalı bilgi” anlamına gelmiyor. RAG pipeline tasarımı büyük ölçüde bu farkı kapatmaya çalışır.
4. Araçlar ve Fonksiyon Tanımları
Modele sunulan araç şemaları da token tüketir. 40 araçtan oluşan bir liste, binlerce token anlamına gelir.
{
"tools": [
{
"name": "search_docs",
"description": "Yalnızca teknik belgelerde arama yapar",
"parameters": { "query": "string" }
}
]
}İyi context engineering, araç tanımlarını iş akışına göre dinamik olarak yükler. Her araç her turda olmak zorunda değil.
5. Konuşma Geçmişi
Önceki mesajlar bağlamı derinleştirir ama token bütçesini hızla tüketir. Basit bir kural: 5-10 tur yeterli, geri kalanı özetlenerek tutulabilir.
if len(history) > 10:
summary = summarize(history[:-5])
history = [{"role": "system", "content": summary}] + history[-5:]Bu beş katmanın toplamı, modelin bir turda gördüğü her şeydir. Context engineering bu toplamı bilinçli tasarlamaktır.
Temel Tasarım İlkeleri
Relevansi Önce
Bağlam penceresine giren her token, modelin dikkat mekanizmasıyla işlenir. Alakasız bilgi dikkat dağıtır ve doğru yanıtın önüne geçer.
Basit test: Eklediğin bilgi çıkarılsaydı model daha kötü yanıt mı verirdi? Hayırsa, çıkar.
Token Bütçesi Yönetimi
128K token penceresi büyük görünür ama pratikte hızla dolar. İyi bir bütçe planı yaklaşık şöyle görünür:
Sistem Promptu : 2.000 token
Statik Bellek : 1.000 token
Dinamik RAG : 8.000 token
Araç Tanımları : 3.000 token
Konuşma Geçmişi : 6.000 token
Yanıt için alan : ~10.000 token
─────────────────────────────────
Toplam : ~30.000 token (muhafazakâr)Bütçeyi aşınca ne olur? Model kesme (truncation) yapar; genellikle en eski veya en az öncelikli içerikten başlar. Bu rastgele bir kesme olduğundan kritik bilgiler kaybolabilir.
Hiyerarşi ve Öncelik
Model, sistem promptunu en yüksek otorite olarak görür. Ama aşağı doğru hiyerarşiyi sen tasarlarsın. Çelişki durumunda ne olur? Bunu açıkça yaz:
Kurallar çelişirse: Güvenlik kuralları > Şirket politikası > Kullanıcı tercihiÇelişki Yönetimi
RAG’den gelen bilgi, sistem promptuyla çelişebilir. Bellek, güncel durumla tutarsız olabilir. Bu çelişkileri önceden ele almak, “ama daha önce şöyle dedin” döngüsünü kırar.
Pratik: AI Agent Context Tasarımı
AI agent mimarileri, context engineering’in en zorlu uygulamasıdır. Ajan birden fazla tur boyunca çalışır; her turda bağlam büyür ve araç çıktıları eklenir.
Müşteri destek ajanı için örnek bir context stack tasarımı:
# Tur 1 başında pencere içeriği
system: |
Sen TechShop müşteri destek ajanısın.
Sipariş sorgularında önce order_db'yi kontrol et.
Kargo sorunlarında shipping_api'yi çağır.
İade talebi varsa, onaylamadan önce kullanıcı kimliğini doğrula.
static_memory:
user_id: "USR-4421"
tier: "premium"
language: "tr"
open_tickets: 0
dynamic_rag:
- source: "iade_politikasi_2026.pdf"
chunk: "Premium üyeler 30 gün içinde ücretsiz iade yapabilir..."
- source: "kargo_gecikme_faq.txt"
chunk: "Kargo 3 iş günü gecikmişse otomatik takip başlatılır..."
tools: ["order_lookup", "shipping_status", "create_ticket"]
history:
- user: "Siparişim nerede?"
- assistant: "Sipariş numaranızı verir misiniz?"
- user: "ORD-88234"Tasarımda birkaç şey öne çıkıyor: araçlar iş akışına özgü seçilmiş, üç taneden fazla değil. Statik bellek kullanıcı kimliğini tuttuğundan her sorguda veritabanına gitmeye gerek kalmıyor. RAG chunk’ları önceden filtre edilmiş, yalnızca ilgili bölümler alınmış.
Ajanlı sistemlerde bir de tur arası bağlam geçişi problemi var. Ajan birden fazla alt görevi sırayla çalıştırıyorsa, önceki adımın çıktısı sonrakine nasıl aktarılır? Her şeyi taşımak bütçeyi patlatır; hiçbir şeyi taşımamak hafızasızlığa yol açar. Çözüm: Her adımın çıktısından kısa, yapılandırılmış özet üret ve bunu bir sonraki turun başına enjekte et.
Yaygın Hatalar
Her Şeyi Sistem Promptuna Tıkmak
“İleride lazım olur” mantığıyla sistem promptu şişirilir. 10.000 token sistem promptu olan sistemlerin çoğunda gerçekten kullanılan kurallar 1.000 tokenlık bir kümeye indirgenebilir.
Belirtim değil kural yaz. “Python’u tercih et” yerine “Python kullan.”
Statik Bağlamı Dinamik Sanmak
Ürün kataloğu veritabanına bağlı değil, sistem promptuna gömülü. Fiyatlar güncellendi ama prompt güncellenmedi. Model hâlâ eski fiyatı söylüyor.
Değişen her bilgi dinamik enjeksiyonla gelmeli; statik bellek sadece nadiren değişen veriler için.
Alakasız RAG Chunk’ları
Benzerlik skoru 0.72 olan ama aslında soruyla ilgisi olmayan bir chunk, modeli yanlış yönlendirir. Yüksek skor relevanslı olmak zorunda değil.
Çözüm: Metadata filtreleme (belge türü, tarih, alan) ve reranker katmanı eklemek. Vektör benzerlik skoru tek başına yetmiyor.
Şişirilmiş Araç Tanımları
Her araç için 500 tokenlik açıklama yazmak, araçların kendisinden daha fazla token tüketir. Araç adı ve kısa parametre listesi genellikle yeterlidir. Modele araç dokümantasyonu değil, kullanım daveti sunuyorsun.
Hata: Konuşma Geçmişini Kesmek
Truncation rastgele yapılırsa kritik bilgiler kaybolur. “Kim olduğumu anlattım, şimdi neden bilmiyor?” şikâyetlerinin büyük bölümü buradan gelir.
Çözüm: FIFO yerine öncelikli kesme. Kullanıcı bilgisi ve açık görevler her zaman korunmalı.
Araçlar ve Frameworkler
Context engineering’i desteklemek amacıyla geliştirilmiş birkaç popüler araç:
LangChain / LangGraph, bağlam yönetimini pipeline olarak tanımlamana izin verir. Memory modülleri, retriever entegrasyonları ve ajan orkestrasyon araçları bir arada. Hızlı prototipleme için iyi, production için dikkatli yapılandırma ister.
LlamaIndex, özellikle RAG pipeline’larında güçlü. Chunk stratejisi, reranker entegrasyonu ve query routing üzerinde ince ayar yapılması gereken ekiplere daha fazla esneklik sunuyor.
DSPy, farklı bir yaklaşım benimser. Prompt yazmak yerine bağlam tasarımını bir optimizasyon problemi olarak ele alır. Hangi bağlam kombinasyonunun en iyi sonucu verdiğini otomatik olarak arar.

Hangi aracın seçileceğinden önce hangi bağlam sorununu çözdüğün daha önemli. Araçlar stratejiyi değiştirmez, uygulama yükünü azaltır.
Bundan Sonra Ne?
Production’da “neden bu kadar kötü yanıt veriyor?” sorusu çoğunlukla bağlam tasarımına gelip dayanır. Token penceresi genişlese de ne koyup ne çıkarılacağı kararı basitleşmiyor.
Pratik bir başlangıç noktası: Mevcut sistem promptunu aç, “Bu kural olmadan model ne kaybeder?” sorusunu her satır için sor. Cevap “hiçbir şey” ise o satırı çıkar.
İlgili konular:
- Sıfırdan AI Agent Yapımı — context engineering’in uçtan uca uygulandığı ana rehber.
- Function Calling ile LLM’leri Sistemlere Bağlamak — bağlamın bir parçası olan tool çıktılarını yönetmek.
- RAG Nedir? Yapay Zekanın Dışarıdan Bilgi Almasını Sağlayan Teknik
- MCP Nedir? Model Context Protocol Rehberi
- Prompt Engineering: İstem Mühendisliği Rehberi



