RAG sistemlerini bir süre kullandıysanız şu soruyla mutlaka karşılaşmışsınızdır: “Bu iki anlaşmayı aynı şirket mi imzaladı?” ya da “Tüm bu araştırma makalelerinin ana tartışma noktası ne?” Vektör aramasına dayalı standart RAG bu noktalarda zorlanır; en yakın metin parçalarını getirir, ama ilişkileri ve geniş kapsamlı örüntüleri kaçırır.
GraphRAG bu sorunu farklı bir yerden çözmeye girişiyor. Microsoft Research’ün 2024’te yayımladığı çalışmaya dayanan bu yaklaşım, belgelerinizi vektöre gömmek yerine içlerindeki varlıkları ve aralarındaki ilişkileri bir bilgi grafiğine dönüştürüyor. Bir LLM’in “bu belgede ne yazıyor?” sorusuna yanıt vermesini sağlamak yerine, belgeler arası “X ile Y nasıl ilişkili?” sorularına da yanıt verebilecek bir yapı kuruluyor.
1. Naive RAG’ın Sınırları
Standart RAG şu şekilde çalışır: belgelerinizi küçük parçalara bölersiniz, bu parçaları vektör veritabanına gömersiniz, sorgu geldiğinde en yakın parçaları çekip yanıt üretirsiniz. Factoid sorularda bu yeterlidir. “Python’un ilk sürümü ne zaman çıktı?” sorusunun yanıtı tek bir cümlede saklıdır ve vektör araması onu bulur.
Bazı soruların yanıtı ise birden fazla belgeye yayılmış ilişkilerde gizlidir. “Bu şirket grubu hangi yatırımcılarla ortak çalışmış?” sorusunu düşünün. Vektör benzerliği size ilgili chunk’ları getirir ama bu chunk’ların birbirine nasıl bağlandığını göremez. “Bu 300 hukuk belgesinde geçen ana ihtilaf türleri nelerdir?” sorusu da aynı şekilde global bir bakış açısı ister; tek tek chunk’lar bu resmi çizemez.
Araştırmacılar bunu iki soru tipi olarak tanımlar: belirli bir varlık hakkındaki lokal sorular ve tüm korpusun yapısını anlamayı gerektiren global sorular. Naive RAG lokal sorularda makul sonuçlar üretir, ama global sorularda elinin yetişemeyeceği mesafeleri vardır. Chunk tabanlı retrieval’ın temel varsayımı “doğru metin parçaları bir arada olursa yanıt çıkar” üzerine kuruludur; bu varsayım ilişkisel sorularda tutmaz.
2. GraphRAG Nedir?
GraphRAG, RAG mimarisinin bilgi grafikleri üzerine inşa edilmiş bir versiyonudur. Microsoft Research’ün “From Local to Global: A Graph RAG Approach to Query-Focused Summarization” başlıklı 2024 makalesinde tanıtılan bu yöntem, belgeleri chunk’lara bölmek yerine içlerindeki varlıkları (entity) ve aralarındaki ilişkileri (relationship) çıkarır; bu yapıyı bir graf veritabanında depolar ve sorgularınızı bu grafik üzerinde yanıtlar.
Fark somut olarak şudur: vektör tabanlı aramada “şu cümleye benzer metin parçaları” bulunur. GraphRAG’da ise “X şirketi Y şirketiyle Z yılında hangi proje kapsamında çalışmıştır” gibi yapılandırılmış ilişkiler sorgulanabilir hale gelir.
Microsoft 2024’te bu çalışmayı açık kaynak olarak yayımladı; graphrag Python kütüphanesi GitHub’da aktif olarak geliştiriliyor. Türkiye’de 2025’ten itibaren özellikle kurumsal bilgi yönetimi, hukuk teknolojisi ve araştırma veritabanı alanlarında sorgu hacminde belirgin artış var.
3. GraphRAG Nasıl Çalışır?
GraphRAG’ın işlem hattı birbirini izleyen beş adımdan oluşur.
Adım 1: Entity ve İlişki Çıkarımı
Ham metin bir LLM’e gönderilir; model metindeki kişileri, organizasyonları, olayları, kavramları ve bunlar arasındaki ilişkileri yapılandırılmış biçimde çıkarır. Sonuç, düğümlerden (varlıklar) ve kenarlardan (ilişkiler) oluşan bir grafik olarak depolanır.
Adım 2: Community Detection
Oluşturulan grafik, Leiden algoritmasıyla topluluklara ayrılır. Bu kümeleme birbirine yakın varlık gruplarını ortaya çıkarır. Hukuk belgelerinde “şirket ağları”, araştırma makalelerinde “araştırmacı toplulukları” gibi doğal kümeler belirir.
Adım 3: Community Report Üretimi
Her topluluk için bir özet rapor üretilir. Bu raporlar global sorguların hammaddesidir; tüm korpusu her seferinde tararken değil, hazır özetler üzerinden çalışılır.
Adım 4: Soru Tipi Tespiti
Sorgu geldiğinde sistem önce onu sınıflandırır: belirli bir varlık veya ilişki hakkında mı (lokal), yoksa tüm korpusun temasını veya örüntüsünü arayan bir soru mu (global)? Bu sınıflandırma hangi retrieval stratejisinin devreye gireceğini belirler.
Adım 5: Retrieval ve Yanıt Sentezi
Lokal sorgularda ilgili varlıklar ve komşuları grafik üzerinden doğrudan alınır. Global sorgularda community report’lar map-reduce tarzında işlenir; her rapor ayrı ayrı özetlenir, ardından bu özetler birleştirilip nihai yanıt kurulur.
Standart RAG’a kıyasla bu süreç hem daha pahalıdır hem de çok daha ilişkisel ve bütünsel sonuçlar üretir.
4. Local ve Global Sorgulama
GraphRAG iki ayrı sorgulama modu sunar. Hangi modu ne zaman kullanacağınızı bilmek sonuçların kalitesini doğrudan etkiler.
Local Search belirli bir varlık veya ilişki hakkında odaklı, hızlı sorgulama içindir. “Ahmet Yılmaz hangi organizasyonlarda görev aldı?” sorusu lokaldır; grafik üzerinden birkaç atlama yapılarak yanıtlanır.
Global Search tüm korpusun yapısını anlamak için tasarlanmıştır. “Bu 300 belgede anlatılan iş modellerinin ortak özellikleri nelerdir?” sorusu globaldir ve community report’ların map-reduce işlemini gerektirir.
Lokal arama daha hızlı ve hesaplama açısından daha ucuzdur. Global arama daha kapsamlıdır ama belirgin biçimde daha yavaştır. İkisini hibrit olarak kullanmak da mümkün; lokal sorgular için vektör araması, geniş kapsam sorular için global mod gibi.
Lokal aramayı somutlaştıralım. Bir hukuk firmasının 500 sözleşmeden oluşan belge tabanını GraphRAG ile indekslediğini düşünün. “Firma X ile imzalanan tüm ödeme koşulları nelerdir?” sorusu lokaldır. Sistem grafik üzerinde “Firma X” düğümünü bulur, bu düğüme bağlı “ödeme koşulu” tipindeki ilişkileri tarar ve birden fazla sözleşmeden gelen ilgili maddeleri tek yanıtta birleştirir. Standart RAG bu soruya da yanıt verir, ama “ödeme koşulu” ifadesi açıkça geçmeyen sözleşmeler kaybolur; graf yaklaşımında ise “Firma X” ile bağlantılı her madde yapısal olarak birbirine bağlıdır ve kayıplar çok daha azdır.
Global arama aynı mantıkla çalışır, ama ölçeği farklıdır. Aynı 500 sözleşmede “tazminat maddeleri açısından en riskli sözleşme kümeleri nelerdir?” sorusu globaldir. Sistem bu soruyu doğrudan yanıtlamak yerine her topluluk raporu üzerinden “bu kümede hangi tazminat örüntüleri var?” sorusunu ayrı ayrı çalıştırır, ardından bu ara yanıtları birleştirerek nihai bir risk özetine ulaşır. Yanıt süresi uzundur ama hiçbir tekil chunk’ın kapsayamayacağı bir panorama elde edersiniz. Hangi modun doğru olduğuna karar verirken sorduğunuz sorunun tek bir varlığa mı yoksa tüm belge kümesine mi yönelik olduğunu düşünün; bu ayrım çoğu durumda yeterlidir.
5. Standart RAG ile Karşılaştırma
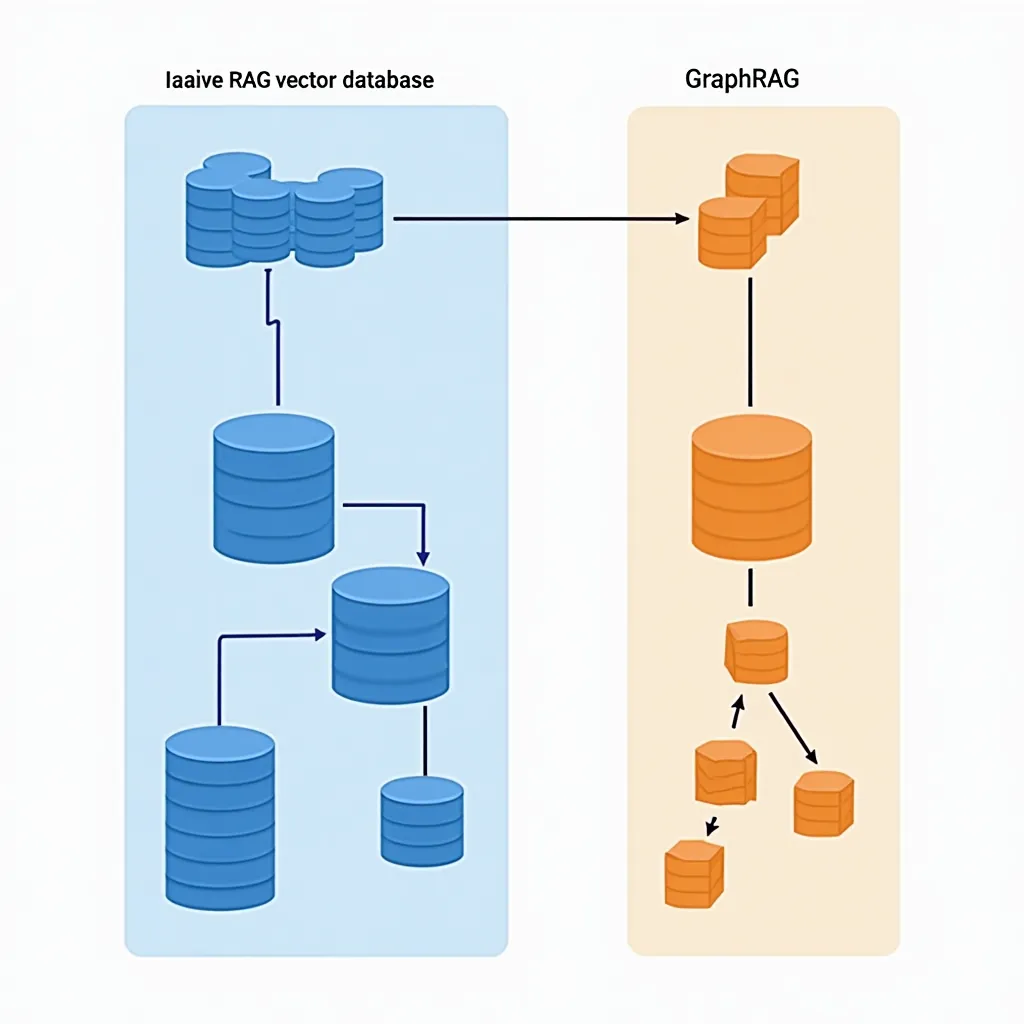
| Özellik | Naive RAG | GraphRAG |
|---|---|---|
| Depolama | Vektör DB (chunk’lar) | Graf DB (entity + ilişki) |
| Sorgulama | Semantik benzerlik | Graf traversal + map-reduce |
| Lokal sorular | İyi | İyi |
| Global sorular | Zayıf | Güçlü |
| İlişkisel sorular | Zayıf | Güçlü |
| Kurulum maliyeti | Düşük | Yüksek |
| Sorgu hızı | Hızlı | Yavaş (global) / Orta (lokal) |
| Embedding modeli ihtiyacı | Zorunlu | Kısmi |
GraphRAG her koşulda daha iyi değildir. Küçük korpuslar, basit factoid sorular ya da düşük gecikmeli uygulamalar için standart RAG hâlâ doğru seçimdir. GraphRAG’ın ek maliyeti iki noktada yoğunlaşır: indeksleme aşamasında (LLM çağrıları pahalıdır) ve global sorgularda (map-reduce yavaştır). Büyük, karmaşık, ilişkisel belgelerle çalışıyorsanız (hukuk, araştırma, kurumsal bilgi yönetimi) bu maliyetin karşılığı çıkar.
6. Microsoft GraphRAG Kütüphanesi ile Hızlı Başlangıç
Microsoft’un açık kaynak kütüphanesi Python üzerinde çalışır. Kurulum tek satırdır:
pip install graphragBir proje dizini oluşturun ve başlatın:
mkdir graphrag-demo && cd graphrag-demo
python -m graphrag init --root .Bu komut bir settings.yml dosyası oluşturur. Temel yapılandırma şöyle görünür:
llm:
api_key: ${GRAPHRAG_API_KEY}
model: gpt-4o
input:
base_dir: "input"
file_pattern: "*.txt"
storage:
base_dir: "output"Belgelerinizi input/ klasörüne koyun, ardından indekslemeyi başlatın:
python -m graphrag index --root .Sorgu için:
# Lokal sorgulama
python -m graphrag query --root . --method local "Microsoft GraphRAG nasıl çalışır?"
# Global sorgulama
python -m graphrag query --root . --method global "Bu belgelerdeki ana temalar nelerdir?"Gerçek dünya kullanım alanları arasında büyük sözleşme paketlerinin analizi, akademik literatür tarama ve kurumsal bilgi tabanı yönetimi öne çıkıyor. Vektör veritabanı altyapısını zaten kurmuş ekipler GraphRAG’ı tamamlayıcı bir katman olarak konumlandırabilir; her iki sistemin paralel çalıştırıldığı hibrit mimariler pratikte tutarlı biçimde iyi sonuç veriyor.
7. GraphRAG Ne Zaman Kullanılmalı?
Bu kararı netleştirecek birkaç soru var:
- Belge sayınız 100’ün üzerinde mi? GraphRAG’ın indeksleme maliyeti bu eşikte haklı çıkmaya başlar.
- Sorgularınız ilişkisel mi? “Kim kimi etkiledi?”, “Bu iki konu nasıl bağlantılı?” gibi sorular bu mimarinin güçlü olduğu alandır.
- Yanıt süresi kritik mi? Milisaniye mertebesinde yanıt gerekiyorsa standart RAG ile başlayın; global GraphRAG sorguları saniyeler içinde ölçülür.
- Tüm korpusu özetleyip genel örüntüler bulmak istiyor musunuz? Global search bunun için var.
Yapay zeka uygulamalarında bilgi katmanını tasarlarken bu dengeyi erkenden kurmak, ilerleyen aşamalarda yeniden mimari için harcanan zamanı kısaltır. Hibrit yapılar da düşünülmeye değer: lokal sorgular için vektör araması, geniş kapsam analizi için GraphRAG global mode. İki yaklaşımı aynı anda desteklemek teknik olarak mümkün ve çoğu kurumsal senaryoda pratik bir seçenek.
Sektöre göre örneklere bakmak bu kararı netleştirir. Hukuk teknolojisinde GraphRAG, yüzlerce sözleşmeyi aynı anda analiz etmek ve taraflar arası ilişki örüntülerini bulmak için iyi bir seçenek. “Bu şirketle tarihsel olarak hangi hukuki anlaşmazlıklar yaşandı?” sorusu standart RAG için çok dağınık; ama bilgi grafiğinde bu bilgi önceden yapılandırılmış. Akademik literatür taramasında da benzer bir tablo var. Yüzlerce makale arasındaki atıf zincirlerini ve araştırmacı ağlarını ortaya çıkarmak için chunk tabanlı retrieval yeterince güçlü değil. “Bu araştırma alanındaki temel fikir ayrılıkları nelerdir?” sorusu global bir sorudur; community detection olmadan yanıtlanamaz.
Kurumsal bilgi tabanlarında GraphRAG, özellikle personel ve proje bilgisinin zaman içinde döküldüğü ortamlarda öne çıkıyor. Kimin kimi tanıdığı, hangi projenin hangi karardan etkilendiği gibi ilişkisel sorular; standart vektör aramasının sınırlarına çok hızlı çarpar. Bu tür bir ortamda GraphRAG’a geçmek indeksleme maliyeti getirir, ama uzun vadede tekrar eden manuel aramaları azaltır.
GraphRAG’ın Mevcut Sınırları
İndeksleme maliyeti ciddidir; büyük bir belge kümesini işlemek hem LLM token’ı hem de zaman gerektirir. Birkaç bin belgeden oluşan bir korpusu indekslemek saatler alabilir ve bunun LLM API maliyeti üzerindeki etkisini başlamadan önce hesaplamak mantıklıdır. Entity çıkarım kalitesi seçilen LLM’e bağlıdır; zayıf bir model yanlış veya eksik ilişkiler üretir ve bu hataların grafiğe yayılması geri dönüşü güç bir sorun çıkarır. Sorgu gecikmesi özellikle global modda yüksektir; kullanıcıya anında yanıt vermenin beklendiği arayüzler için uygun değildir. Kütüphanenin bakımı Microsoft Research ekibine bağlıdır; production’a taşımadan önce community sürümünün güncel desteğini kontrol edin.
Bu kısıtlar GraphRAG’ı değersiz kılmaz; sadece hangi probleme uygun olduğunun sınırlarını çizer. Doğru senaryoda, yani büyük ve ilişkisel bir belge kümesiyle çalışırken, bu ek karmaşıklık karşılığını verir.
GraphRAG, standart RAG’ın ilişkisel ve global sorulardaki kör noktasını gidermek için tasarlanmış belirli bir mimari tercih. Küçük korpuslar ve hızlı factoid sorular için fazla karmaşık. Büyük, yapılandırılmamış belge yığınlarını anlamlı bilgiye dönüştürmeniz gerekiyorsa ve sorgularınız ilişkisel veya global karakterdeyse, entity-relationship grafı tabanlı bu yaklaşım işe yarar.
Microsoft’un graphrag GitHub deposunu inceleyebilir ya da bu sitedeki RAG rehberinden başlayabilirsiniz.