list_altİçindekilerexpand_more
Uzun bir PDF’yi ChatGPT’ye yapıştırdınız ve şu hatayla karşılaştınız: “This model’s maximum context length is X tokens.” Ya da Claude’a 50 sayfalık bir sözleşme göndermek istediniz ama API faturanız beklentinizin üç katı geldi. Her ikisinde de sorumlu aynı kavram: token.
Token, büyük dil modellerinin temel ölçü birimi. Maliyet bununla hesaplanır, limit bununla belirlenir. Ama çoğu geliştirici “token nedir” sorusunu atlayıp doğrudan API’yi kullanmaya başlar. Fatura gelince şaşırırlar.
Bu yazı tokenizasyonun nasıl çalıştığını, Türkçe’nin neden İngilizce’ye kıyasla daha fazla token harcadığını, 2026 fiyat tablosunu ve faturaları küçültmek için ne yapılabileceğini ele alıyor.
Token Nedir? Kelime mi, Harf mi?
Token ne bir kelimedir ne de tek bir harf. LLM’in metni işlediği en küçük parça olan token, duruma göre bir kelime, bir hece ya da bir noktalama işareti olabilir; ama kesin sınır kullanılan tokenizer’a göre değişir.
GPT-4o’nun tokenizer’ında:
- “hello” → 1 token
- “tokenization” → 3 token (
token,iz,ation) - “2026” → 1 token
- ”…” → 1 token
- “merhaba” → 2 token (
mer,haba)
Sayılar genellikle 1-3 basamak = 1 token kuralına uyar. Boşluklar önündeki kelimeyle birleşebilir (▁hello gibi). Noktalama işaretleri ayrı token sayılır.
Türkçe’nin token verimsizliği tam burada kendini gösterir. “Gidebileceklerindendi” tek bir sözcük, ama GPT-4o tokenizer’ında 6-7 tokena bölünür. Bu token sözlüğü ağırlıklı olarak İngilizce metinlerle oluşturulmuş; Türkçe’nin aglütinatif yapısını temsil edecek yeterli alt-kelime birikimi yok.

Rakamlar ve sembollerin tokenizasyonu da sezgisel değil. “1000000” bazen tek bir token, bazen birkaç token olabilir. Aynı sözcük, başında boşluk varsa farklı bir token ID’si alır. Bu nüanslar büyük ölçekte çalışırken token bütçesi hesaplamalarını etkiler.
Tokenizasyon Nasıl Çalışır? BPE ve SentencePiece
Neden sesli harflere ya da hecelere bölünmüyor? Neden kelime sözlüğü kullanılmıyor?
Karakter düzeyinde bölünme aşırı uzun diziler üretir; modelin her adımda çok daha fazla işlem yapması gerekir. Sözcük düzeyinde bölünme ise milyonlarca nadir kelimeyi sözlüğe eklemek zorunda bırakır, bu da hem bellek hem de genelleme açısından sorunludur. İkisinin ortasındaki yol Byte Pair Encoding (BPE).
BPE algoritması şu adımlarla çalışır: Önce tüm eğitim metnindeki karakterlerle başlanır. Ardından en sık birlikte geçen karakter çifti tek bir sembol olarak birleştirilir. Bu adım belirlenen sözlük boyutuna ulaşılana kadar tekrarlanır. GPT ailesi bu yöntemi tiktoken kütüphanesiyle kullanır.
# Kavramsal BPE adımları
# Başlangıç: ['l', 'o', 'w', 'e', 's', 't']
# En sık çift: ('e', 's') → birleştirilir → 'es'
# Sonraki sık çift: ('es', 't') → 'est'
# Sonuç: "lowest" → ["low", "est"]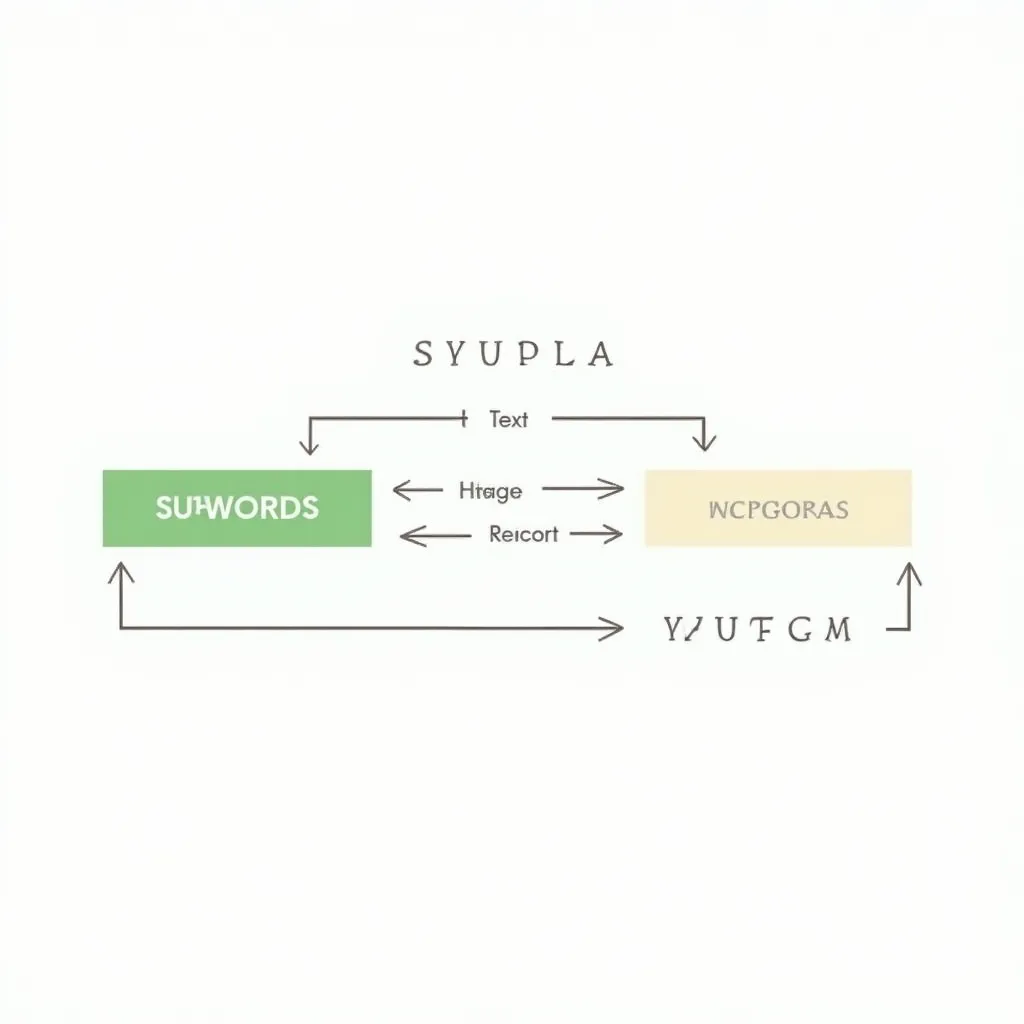
Llama, Gemma ve birçok açık kaynak model ise SentencePiece tokenizer’ı tercih eder. Teknik fark önemli: SentencePiece ham Unicode baytları üzerinde çalışır, metni önceden boşluklara göre bölmez. Japonca, Çince ve Türkçe gibi dillerde bu yaklaşım farklı sonuçlar üretir.
Farklı modeller arasında token sayısı aktarılamaz. GPT-4o için hesapladığınız token miktarı, Llama 3.3’te farklı çıkabilir. API çağrılarınızın maliyetini doğru tahmin etmek istiyorsanız hedef modelin tokenizer’ını kullanmalısınız.
Bağlam Penceresi (Context Window) Nedir?
LLM’e gönderdiğiniz sistem promptu, kullanıcı mesajları ve modelin ürettiği yanıtların tamamı aynı havuza girer: bağlam penceresi. Modelin tek bir işlemde görebildiği maksimum token sayısı bu pencerenin kapasitesini belirler.
2026 itibarıyla önde gelen modellerin kapasiteleri:
| Model | Context Window |
|---|---|
| GPT-4o | 128.000 token |
| Claude Opus 4.7 | 200.000 token |
| Gemini 2.5 Pro | 1.000.000 token |
| Llama 3.3 70B | 128.000 token |
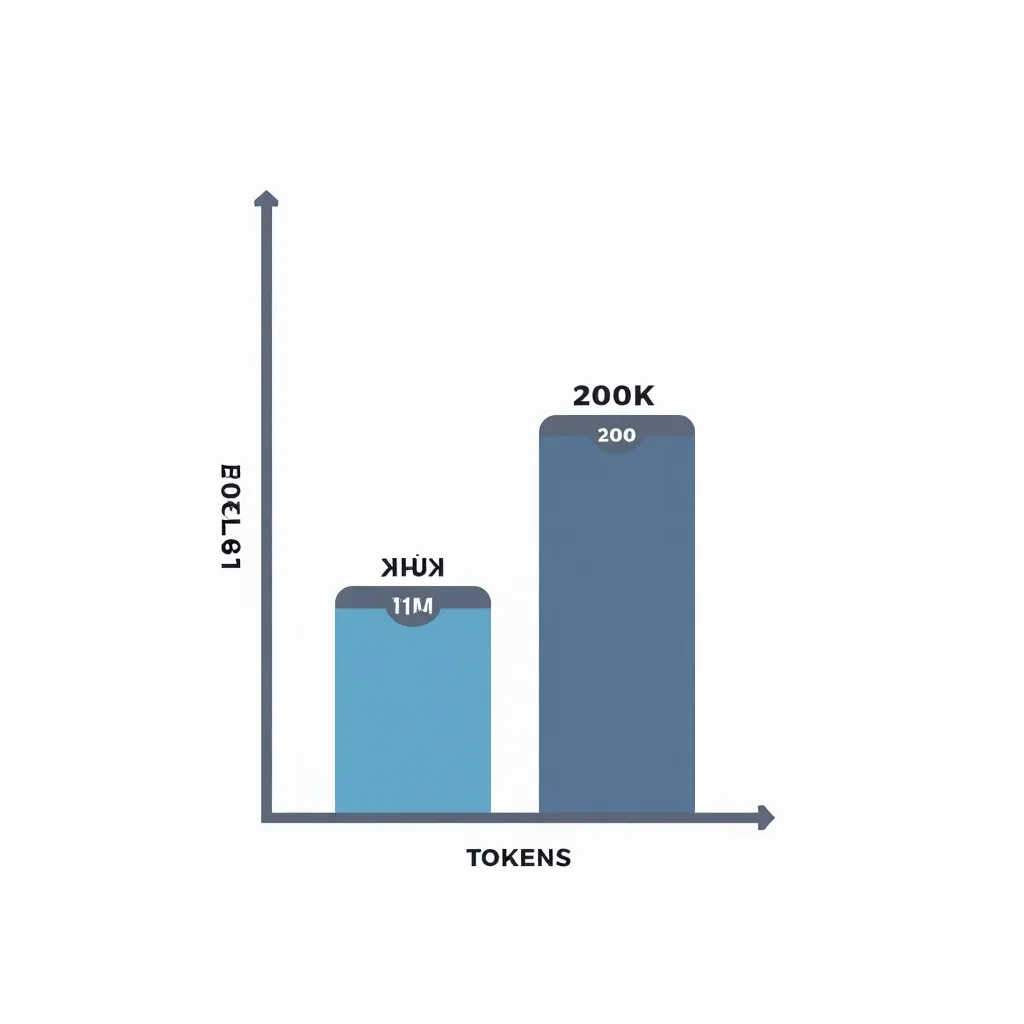
Pencerenin dolmasıyla ne olur? İki seçenek var: truncation veya hata. Truncation genellikle en eski konuşma turlarının atılması anlamına gelir ve modelin hafızası kaybolur. Hata durumunda API çağrısı başarısız döner.
Bağlam penceresinin büyüklüğü bir teknik sınırdan ibaret değil, aynı zamanda bir maliyet faktörü. Attention mekanizması bağlam uzunluğuyla karesel (O(n²)) ölçeklenir. 200K token işlemek, 100K tokenden dört kat daha fazla hesaplama gerektirir. Bu yüzden uzun bağlamlı işlemler kısa olanlara kıyasla çok daha pahalıdır.
Bağlam penceresinin tamamını doldurmanıza gerek yok. Gerekli bilgileri seçici biçimde iletmek hem maliyet hem yanıt kalitesi açısından daha iyi sonuç verir. Uzun bir dökümanın tamamı yerine ilgili bölümleri kesmek, modeli hem daha odaklı hem daha hesaplı kılar.
Türkçe Metin Neden Daha Fazla Token Harcıyor?
Türkçe, aglütinatif bir dil. Tek bir kelime, İngilizce’de birkaç ayrı kelimeyle karşılanabilen anlamları bir arada barındırır.
“Gidebileceklerindendi” yaklaşık olarak “It was from those who would be able to go” anlamına gelir; GPT-4o’da bu tek sözcük 6-7 tokena bölünür.
BPE sözlükleri İngilizce ağırlıklı eğitildi. “Going” veya “walked” gibi İngilizce sözcükler genellikle tek bir token. Türkçe’nin uzun ek zincirleri BPE sözlüğünde tam olarak yer bulmaz; kelimeler alt-parçalara ayrılır.
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4o")
tr_text = "Yapay zeka modelleri metni verimli biçimde işler."
en_text = "Artificial intelligence models process text efficiently."
tr_token_count = len(enc.encode(tr_text))
en_token_count = len(enc.encode(en_text))
print(f"Türkçe: {tr_token_count} token") # ~11
print(f"İngilizce: {en_token_count} token") # ~8Ortalama olarak Türkçe metinler, aynı anlam yoğunluğundaki İngilizce metinlere göre yüzde yirmi ile kırk arasında daha fazla token harcar. Bu fark büyük ölçekli uygulamalarda ciddi bir maliyet kalemine dönüşür.
Çözüm seçenekleri arasında Türkçe verilerle ince ayar yapılmış modeller, prompt sıkıştırma teknikleri ve sistematik token ön-optimizasyonu var. Türkçe’ye özel tokenizer sözlükleri kullanıma girdiğinde bu farkın kapanması bekleniyor.
Token Maliyeti Nasıl Hesaplanır?
Token fiyatlandırması genellikle “1 milyon token başına dolar” ($/M tok) cinsinden ifade edilir. Input (girdi) ve output (çıktı) tokenları ayrı ayrı fiyatlanır; output tokenları genellikle 3-5 kat daha pahalıdır.
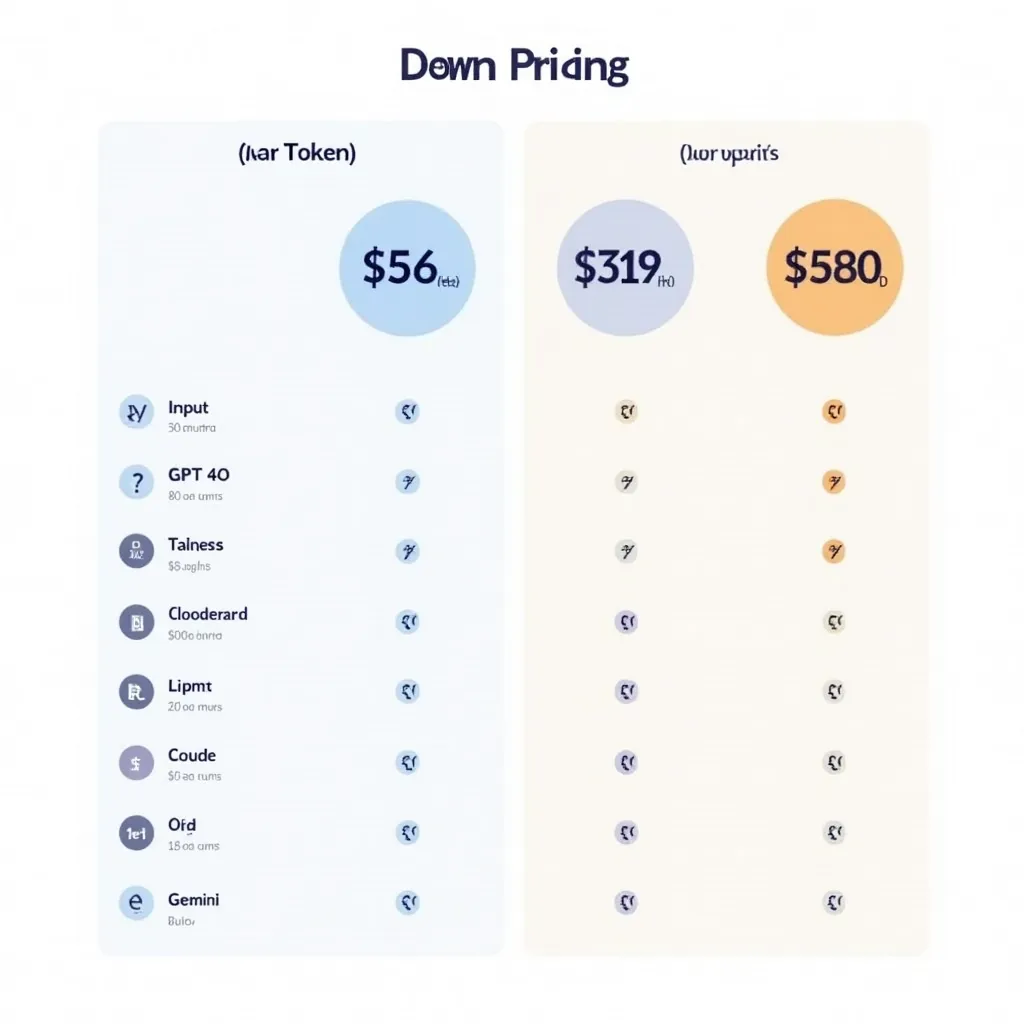
2026 başı itibarıyla yaklaşık fiyatlar (kesin rakamlar için sağlayıcı sayfalarını kontrol edin):
| Model | Input ($/M tok) | Output ($/M tok) |
|---|---|---|
| GPT-4o | $2.50 | $10.00 |
| Claude Opus 4.7 | $15.00 | $75.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Gemini 2.5 Pro | $1.25 | $10.00 |
| Llama 3.3 70B (API) | $0.20 | $0.60 |
Örnek senaryo: Aylık 1.000 kullanıcı, günde 5 mesaj, ortalama 2.000 input + 500 output token.
- Aylık toplam input token: 1.000 x 5 x 30 x 2.000 = 300.000.000 token
- Aylık toplam output token: 1.000 x 5 x 30 x 500 = 75.000.000 token
GPT-4o ile maliyet:
- Input: 300M x $2.50 / 1M = $750
- Output: 75M x $10.00 / 1M = $750
- Toplam: ~$1.500/ay
Aynı yük için Claude Sonnet 4.6:
- Input: $900 + Output: $1.125 = ~$2.025/ay
Model seçimi ve prompt optimizasyonu birlikte uygulandığında aylık fatura önemli ölçüde düşer. Prompt caching bu denklemi de değiştirir. Claude’un cache_control özelliği ve OpenAI’nin cached input pricing’i tekrarlayan sistem promptları için yüzde yetmişbeşe varan indirim sunar.
tiktoken ile Token Sayma: Pratik Rehber
tiktoken, OpenAI’nin GPT ailesinde kullandığı tokenizer’ın açık kaynak Python uygulaması.
pip install tiktokenimport tiktoken
# GPT-4o için encoding (o200k_base kullanır)
enc = tiktoken.encoding_for_model("gpt-4o")
metin = """
Yapay zeka dil modelleri, metni token adı verilen parçalara bölerek işler.
Bu süreç tokenizasyon olarak bilinir ve modelin anlayışının temelini oluşturur.
"""
tokens = enc.encode(metin)
print(f"Token sayısı: {len(tokens)}")
# Token ID'lerini metne geri çevir
for token_id in tokens[:5]:
print(f" {token_id} → '{enc.decode([token_id])}'")GPT-4 Turbo ve GPT-4o o200k_base encoding kullanır. Eski GPT-3.5 ve GPT-4 modelleri cl100k_base. Bu fark nadiren kritik önem taşısa da kesinlik istiyorsanız encoding_for_model() kullanın, get_encoding() değil.
Claude için Anthropic’in kendi token sayacı var:
import anthropic
client = anthropic.Anthropic()
response = client.messages.count_tokens(
model="claude-opus-4-7-20251101",
messages=[
{"role": "user", "content": "Tokenization nedir ve neden önemlidir?"}
]
)
print(f"Input token sayısı: {response.input_tokens}")Çok adımlı konuşmalarda token birikimini takip etmek kritik. Her tur hem önceki mesajları hem de yeni mesajı içerir. 10 turlu bir konuşmada toplam token bütçesi doğrusal değil, kümülatif artar.
Web arayüzü tercih edenler için OpenAI’nin Tokenizer sayfası gerçek zamanlı token görselleştirme sunar; metni yapıştırıp her token parçasının farklı renkte gösterildiğini izleyebilirsiniz.
Token Optimizasyon Stratejileri
Aşağıdaki altı yöntem çoğu uygulamada hemen uygulanabilir.
Sistem promptunu kısaltın. Uzun ve tekrarlayan talimat blokları her API çağrısında aynı tokenlara para ödetir. Boilerplate kısmı sıkıştırın, örnekler yerine kısa kurallar yazın. Sistem promptunu 500 tokenın altında tutmak iyi bir hedef.
Output formatını belirtin. “Açıklayınız” yerine “madde işaretleriyle 5 noktada özetle” yazın. Model kısa ve yapılandırılmış yanıt verdiğinde output token sayısı düşer; bu en hızlı ROI sağlayan optimizasyon.
Dökümanları önceden temizleyin. HTML veya PDF’den metin çıkarırken tüm tag’leri, whitespace’i ve tekrarlayan başlıkları temizleyin. Basit bir regex ile yüzde yirmi ile otuz arasında token tasarrufu mümkün.
import re
def temizle(html: str) -> str:
html = re.sub(r"<[^>]+>", " ", html) # HTML tag'lerini sil
html = re.sub(r"\s+", " ", html) # Fazla boşlukları kapat
return html.strip()Prompt caching kullanın. Claude’da cache_control ile sistem promptunu ve uzun dökümanları cache’e alın. OpenAI’de 1.024 token üzeri input’lar otomatik cached input pricing’e girer.
# Claude cache_control örneği
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": sabit_sistem_promptu,
"cache_control": {"type": "ephemeral"}
},
{
"type": "text",
"text": kullanici_sorusu
}
]
}
]RAG chunk boyutunu optimize edin. RAG pipeline’ında çok büyük chunk’lar gereksiz token harcar. 512-1.024 token arası chunk boyutu, hem arama kalitesi hem maliyet açısından iyi bir denge sunar.
Model seçimini göreve göre yapın. Sınıflandırma, özetleme ve basit soru-cevap için Claude Haiku 4.5 ya da GPT-4o mini kullanmak, Opus veya GPT-4o’ya kıyasla 10-20 kat maliyet avantajı verir. Her görev için en büyük modele gerek yok.
Tokenizasyonu anlamak, bir LLM uygulaması geliştirirken kaçınılmaz bir adım. Token sayısını bilmeden sistem tasarlamak, fatura gelince sürpriz yaşamak demek. Yukarıdaki araçlar ve yöntemler bu belirsizliği ortadan kaldırır.
Bu yazıda kullanılan terimlerin kısa tanımlarına Yapay Zeka Sözlüğü üzerinden ulaşabilirsiniz. Token, context window ve RAG maddeleri bu konuyla doğrudan bağlantılı.



