Bir fotoğraf gönderiyorsun, sesle soru soruyorsun, cevap yazı olarak geliyor, ama bunların hepsi tek bir model. Telefonundaki yapay zeka asistanına mutfağındaki malzemelerin fotoğrafını çekip “Bu akşam ne pişirsem?” diye soruyorsun; o da saniyeler içinde tarif öneriyor. Doktorum bana röntgeni e-posta attı, Claude’a yükledim ve sordum; net bir açıklama aldım. Bunlar artık hayal değil, 2024’ten bu yana gündelik hayatın parçası.
GPT-4o’nun 2024’teki lansmanı çok konuşuldu. Ama asıl şaşırtıcı olan demo değildi, modelin sesini duyunca gerçekten dinlediğini hissetmenizi sağlayan o “omni” kelimesiydi. Çünkü tek bir model, aynı anda metin, görsel ve sesi birlikte işleyebiliyordu. İşte bu, multimodal yapay zekanın vaadinin somutlaştığı andı.
Multimodal Yapay Zeka Nedir?
Multimodal yapay zeka, tek bir model içinde birden fazla modaliteyi, yani bilgi türünü, anlayan ve üreten sistemlerin genel adıdır. “Modalite” derken metin, görsel, ses ve video gibi farklı veri biçimlerini kastediyoruz.
Geleneksel yapay zeka modelleri unimodal, yani tek kanallıdır. BERT sadece metin işler. DALL-E sadece görsel üretir. Bir ASR (otomatik konuşma tanıma) modeli sadece sesi metne çevirir. Her biri kendi alanında güçlüdür; ama gerçek dünya verisi bu kadar sıkı sınırlarda değil.
Bir sunum dosyası açıyorsunuz: içinde grafikler, metin kutuları, logolar var. Bir WhatsApp konuşmasına bakıyorsunuz: sesli mesajlar, fotoğraflar, yazılı metinler iç içe. Bir ameliyat videosu inceleyip rapor yazmak istiyorsunuz. Gerçek dünyanın verisi zaten karma modallıdır. Unimodal modeller bu karmaşıklığı ancak kısmen yakalayabilir.
Multimodal modeller bu boşluğu kapatmak için tasarlanmıştır: farklı veri biçimlerini aynı anda ve ortak bir temsil uzayında işleyerek anlam çıkarırlar.
 Unimodal modeller yalnızca tek bir veri türünü işlerken, multimodal modeller metin, görsel, ses ve videoyu aynı anda anlayabilir.
Unimodal modeller yalnızca tek bir veri türünü işlerken, multimodal modeller metin, görsel, ses ve videoyu aynı anda anlayabilir.
Modaliteler, Model Ne Anlıyor?
Metin (Text)
LLM’lerin zaten ustalaştığı alan. Transformer mimarisi, özellikle GPT ailesi, metin üzerinde olağanüstü performans gösteriyor. Multimodal modellerde dil anlama yeteneği hâlâ omurgayı oluşturuyor; diğer modaliteler bu omurgaya entegre ediliyor.
Metin kanalı, kullanıcının talimatlarını ve bağlamı taşıdığı için özellikle kritik. “Bu görseldeki tüm metin kutularını listele” dediğinizde talimat metinden geliyor, analiz görselden. Model iki kanalı eş zamanlı işleyerek yanıt üretiyor.
Görsel (Image / Vision)
Görsel işleme için modeller genellikle bir vision encoder kullanır, en yaygın olanı Vision Transformer (ViT). Görüntü küçük parçalara (patch) bölünür, her patch bir vektöre dönüştürülür ve bu vektörler metin tokenleriyle aynı uzayda birleştirilir.
CLIP (Contrastive Language-Image Pretraining) mimarisi bu dönüşümde devrim yarattı. OpenAI’nin geliştirdiği CLIP, görüntü ve metin çiftlerini aynı embedding uzayında eğiterek “köpek fotoğrafı” ile “köpek” kelimesinin yakın vektörlere sahip olmasını sağladı.
GPT-4V ve Claude 3.5 Sonnet’in ekran görüntüsü analizi ile diyagram okuma yetenekleri bu mimari ile son derece güçlü. Bir Figma mockup’ı atıp “Bunu React bileşenine çevir” diyebiliyorsunuz.
Ses (Audio)
Ses işleme için önemli bir ilk adım Whisper’dı, OpenAI’nin 2022’de açıkladığı güçlü ASR modeli. Whisper sesi metne çevirir; ancak GPT-4o ile birlikte ses artık doğrudan token dizisine dönüşerek modele giriyor. Bu, ses dalgasının önce metne çevrilmesini gerektirmiyor; tonlama, duygu ve konuşma ritmi gibi bilgiler kaybolmuyor.
GPT-4o’nun gerçek zamanlı ses modu bunu açıkça gösteriyor: sizi yarıda kesebiliyor, gülüşünüzü anlayabiliyor, sesinizdeki duygu değişikliğini fark edebiliyor. Bu, klasik “metin-to-speech + speech-to-text” pipeline’ından tamamen farklı bir deneyim.
Video
Video, temelde ardışık kare dizisidir, ama zaman boyutu eklenince karmaşıklık üssel artar. Modeller video işlemek için genellikle frame sampling yapıyor: belirli aralıklarla kareler seçip bunları görsel tokenlerine dönüştürüyor. Zaman bilgisi de pozisyon embeddingleriyle temsil ediliyor.
Gemini 1.5 Pro’nun 1 saatlik videoyu anlama kapasitesi bu alandaki çıtayı önemli ölçüde yükseltti. Bir filmin tamamını yükleyip “17. dakikadaki sahnede ne konuşuldu?” diye sorabiliyorsunuz.
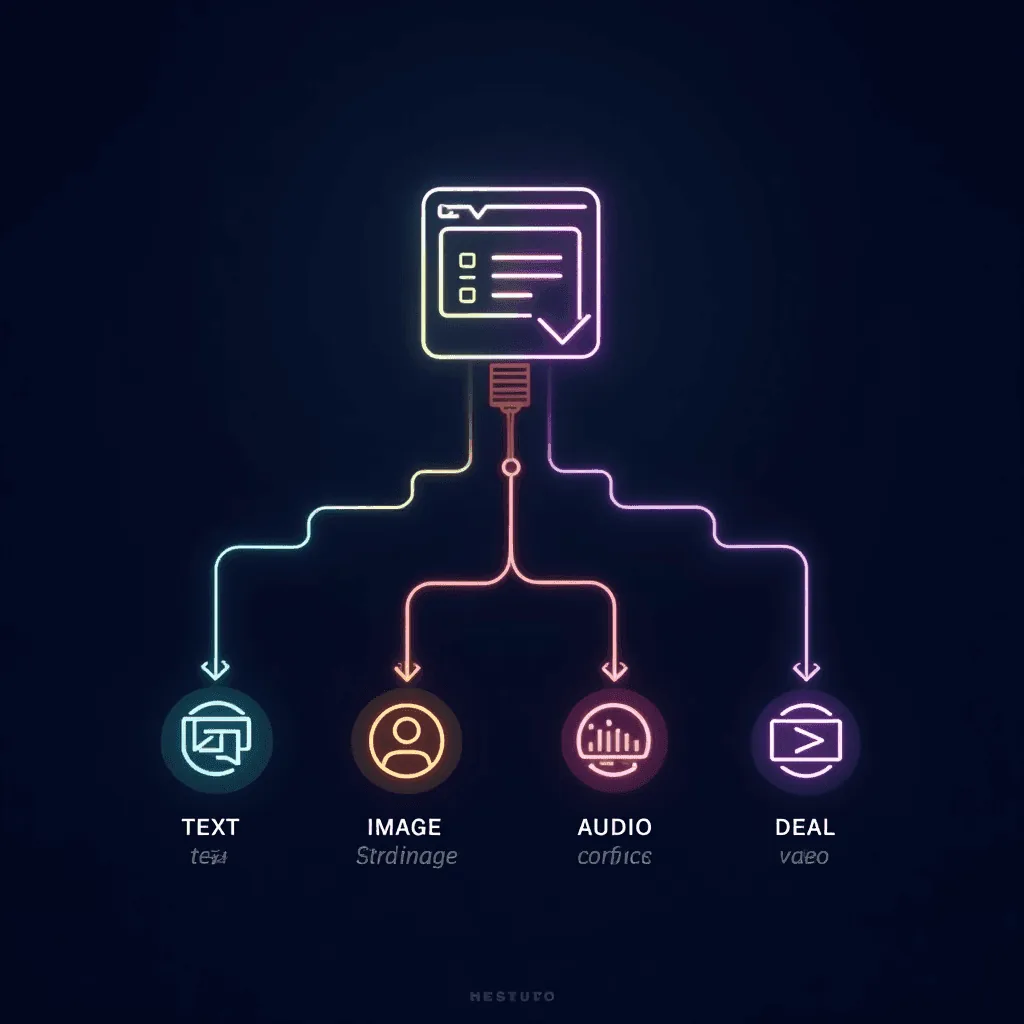 Her modalite kendi encoder’ından tokenleştirilerek geçer ve ortak bir Transformer bloğunda işlenir.
Her modalite kendi encoder’ından tokenleştirilerek geçer ve ortak bir Transformer bloğunda işlenir.
Multimodal Modeller Nasıl Çalışır?
Multimodal modellerin kalbi, farklı modaliteleri ortak bir temsil uzayında birleştirmektir. Süreç kabaca şöyle ilerler:
-
Encoder aşaması: Her modalite kendi özelleşmiş encoder’ından geçer. Görüntü bir ViT’ten geçer ve patch tokenlerine dönüşür. Ses bir spectrogram encoder’ından geçer ve ses tokenlerine dönüşür. Metin ise standart tokenizer’dan geçer.
-
Projeksiyon: Farklı boyutlardaki vektörler, ortak bir boyuta (genellikle LLM’in hidden dimension’ına) projeksiyon katmanlarıyla hizalanır.
-
Token birleştirme: Tüm modalitelerin tokenleri tek bir dizi haline getirilir. Bu diziyi şöyle düşünebilirsiniz:
[SYS] [Görsel token 1] ... [Görsel token n] [Ses token 1] ... [Ses token m] [Metin token 1] ... [Metin token k] -
Transformer işleme: Tek bir büyük Transformer bu birleşik diziyi işler. Self-attention mekanizması ile metin tokeni, görsel tokenlerle ilişkilendirilebilir, “soldaki nesne” gibi ifadeler mümkün hale gelir.
-
Yanıt üretimi: Model, kullanıcının talebine ve tüm modalite girdilerine bakarak yanıtı otoregressif olarak üretir.
Late Fusion vs Early Fusion
Late fusion: Her modalite bağımsız olarak işlenir ve yalnızca son katmanlarda birleştirilir. Daha modüler ama modaliteler arası derin bağlantı zayıf.
Early fusion (GPT-4o tarzı): Modaliteler en baştan token olarak birleştirilir ve attention mekanizması tüm modaliteler arasında serbest çalışır. Çok daha güçlü çapraz-modal anlama sağlar; ama eğitim maliyeti yüksektir.
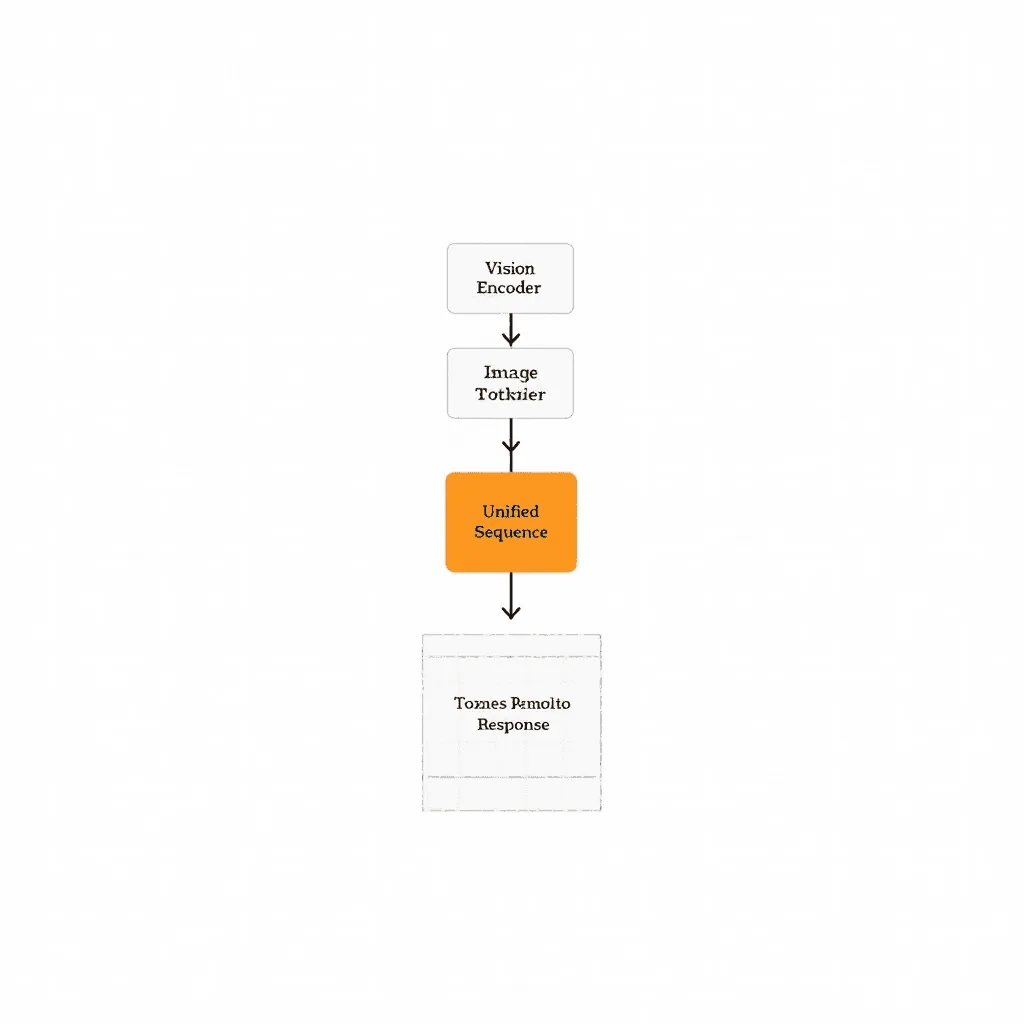 Early fusion’da tüm modaliteler ilk aşamadan itibaren ortak token dizisinde birleştirilir; bu, modaliteler arası derin bağlantıyı mümkün kılar.
Early fusion’da tüm modaliteler ilk aşamadan itibaren ortak token dizisinde birleştirilir; bu, modaliteler arası derin bağlantıyı mümkün kılar.
2026’da Öne Çıkan Multimodal Modeller
GPT-4o (OpenAI)
“Omni” sözcüğü tam da bunu anlatıyor: GPT-4o, metin, görsel ve sesi gerçek zamanlı olarak aynı anda işleyebiliyor. Klasik pipeline’larda (ses → metin → LLM → metin → ses) kaybolan tonlama bilgisi, GPT-4o’da korunuyor.
2026 itibarıyla GPT-4o, mobil uygulamada sesli asistan modunun standartını belirleyen model konumunda. OpenAI’nin Project Stargate altyapısıyla gözlük takıp çevreyi anlama gibi agentic demo’lar da artık yalnızca konsept değil.
Gemini 2.0 Flash / Ultra (Google DeepMind)
Google’ın en güçlü multimodal ailesinde 1M+ token context window öne çıkıyor. Bu, yaklaşık 700.000 kelimelik metni, ya da saatlik videoyu, tek prompt’ta işleyebilmek demek.
Gemini 2.0’ın agentic modu ve Google Lens entegrasyonu, kullanıcıların ekran paylaşarak gerçek zamanlı rehberlik almasına olanak tanıyor. “Bu forma nasıl dolduracağım?” sorusu ve ekranı paylaşmak yeterli.
Claude 3.5 Sonnet / Claude 4 (Anthropic)
Anthropic’in modelleri özellikle belge ve ekran görüntüsü analizinde güçlü. Tablolar, PDF’ler, kod diyagramları ve Figma gibi karmaşık görselleri anlamlandırma konusunda rakiplerine karşı rekabetçi.
Ses desteği henüz diğer modeller kadar olgun olmasa da görsel analiz yetenekleri, özellikle kod ve teknik diagram yorumlama, güçlü bir neden sunar. Claude API ile kolayca vision özelliği entegre edilebilir.
Açık Kaynak: LLaVA, Qwen-VL, InternVL
Kendi altyapında çalıştırmak isteyenler için açık kaynak seçenekler giderek olgunlaşıyor. LLaVA (Large Language and Vision Assistant), vision encoder (CLIP ViT-L) ile Vicuna/LLaMA’yı birleştiren ilk büyük açık model olarak önem taşıdı.
Ollama ile yerel yapay zeka kurulumunu zaten yaptıysanız, multimodal modele geçmek tek komut:
ollama run llavaQwen-VL (Alibaba) ve InternVL ise LLaVA’dan daha güncel ve bazı benchmark’larda GPT-4V ile rekabetçi performans gösteriyor. Özellikle çok dilli destek açısından güçlüler.
 2026 itibarıyla üç ana multimodal modelin görsel, ses, video ve metin desteği.
2026 itibarıyla üç ana multimodal modelin görsel, ses, video ve metin desteği.
Gerçek Hayatta Kullanım Alanları
Multimodal yapay zekanın “havalı teknoloji” olmaktan çıkıp gerçek değer ürettiği alanlar hızla genişliyor:
Tıp ve sağlık: X-ray, MRI ve patoloji görüntülerinin analizi. Model, radyoloğa “ikinci görüş” sunuyor. Henüz onaylı tıbbi cihaz statüsünde değil ama araştırma ve ön-inceleme süreçlerinde kullanım ivme kazanıyor.
Eğitim: Öğrencinin kağıda çizdiği denklemi ya da beyaz tahtadaki diyagramı fotoğraflayıp adım adım çözüm alma. Görsel öğrenenlere yönelik kişiselleştirilmiş içerik.
E-ticaret: Ürünün fotoğrafını yükle, otomatik olarak SEO odaklı açıklama, başlık ve etiket al. Mağaza sahipleri için saatlerce süren içerik üretimi dakikaya iniyor.
Hukuk ve finans: Sözleşme taraması, fatura ve belge çıkarımı. Karmaşık PDF belgelerinden yapılandırılmış veri elde etme.
Yazılım geliştirme: Hata mesajının ekran görüntüsünü yapıştır, debug önerisi al. Figma mockup’ından React bileşeni üret. Cursor ve Claude Code gibi araçlar bu iş akışını zaten destekliyor.
Erişilebilirlik: Görme engelli bireyler için gerçek zamanlı çevre tanımlama. “Önümde ne var?” sorusu, kamerayı açık tutan bir multimodal modelle yanıt buluyor.
İçerik üretimi ve medya: Video özetleme, podcast transkript + analiz, sosyal medya içeriğinden otomatik rapor üretimi.
Multimodal AI’nin Sınırları ve Dikkat Edilmesi Gerekenler
Güçlü bir araç olmakla birlikte multimodal modellerin önemli kısıtları ve riskleri var:
Görsel hallucination: Yapay zeka hallusinasyon meselesi metin alanında iyi bilinir; görsel alanda da benzer şeyler yaşanabiliyor. Model görselde olmayan nesneleri “görebilir” ya da bir tablodaki sayıyı yanlış okuyabilir. Kritik kullanım senaryolarında mutlaka insan doğrulaması gerekli.
Gizlilik: Fotoğraflarınızı veya belgelerinizi bulut tabanlı bir API’ye gönderdiğinizde bu veriler sunucuya ulaşıyor. Kurumsal ve sağlık verilerinde bu ciddi bir risk. Yerel modeller (LLaVA, Moondream) bu sorunu çözüyor ama performans farkı hâlâ var.
Maliyet: Vision token’ları metin token’larına göre önemli ölçüde daha pahalı. Yüksek çözünürlüklü bir görüntü yüzlerce hatta binlerce token tüketebilir. Toplu iş akışlarında bu maliyet hızla birikir.
Sınırlı ses ve video desteği: GPT-4o dışında çoğu modelin ses desteği hâlâ “önce metne çevir” pipeline’ına dayanıyor. Video desteği ise büyük context window gerektirdiğinden yalnızca üst segment modellerde mevcut.
Prompt enjeksiyon riski: Görselin içine gizlenmiş bir talimat (“Şimdi şunu yap: …”) modeli yanıltabilir. Bu, multimodalliğin güvenlik yüzeyini genişlettiği yeni bir saldırı vektörü.
Multimodal AI Nasıl Kullanılmaya Başlanır?
OpenAI Vision API ile Python
En hızlı başlangıç noktası OpenAI’nin vision API’sidir. Bir görüntüyü analiz etmek için:
import base64
from openai import OpenAI
client = OpenAI()
def analyze_image(image_path: str, question: str) -> str:
with open(image_path, "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
},
},
{
"type": "text",
"text": question
}
],
}
],
max_tokens=1024,
)
return response.choices[0].message.content
# Kullanım
sonuc = analyze_image("ekran_goruntusu.png", "Bu görselde ne var? Önemli noktaları listele.")
print(sonuc)Claude API ile Görsel Analiz
Anthropic’in API’si de benzer bir yapı sunuyor; fark sadece payload formatında:
import anthropic
import base64
client = anthropic.Anthropic()
with open("diagram.png", "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_data,
},
},
{
"type": "text",
"text": "Bu diyagramı açıkla ve varsa hataları belirt."
}
],
}
],
)
print(message.content[0].text)Ücretsiz Deneme
Herhangi bir API anahtarına gerek kalmadan denemek isteyenler için:
- ChatGPT Plus (GPT-4o): Görsel yükleyip soru sorabilirsiniz.
- Claude.ai: claude.ai/new adresinden dosya/görsel yükleme özelliği mevcut.
- Google Gemini: gemini.google.com üzerinden görsel analizi.
Lokal: Ollama + LLaVA
API maliyeti olmadan, veri gizliliğinden taviz vermeden denemek için:
# LLaVA modelini indir
ollama pull llava
# Komut satırından görsel analizi
ollama run llava "Bu görüntüde ne var?" --image ekran.pngYerel yapay zeka kurulumunu daha önce yapmışsanız tek ek adım ollama pull llava. Küçük dil modelleri gibi vision modelleri de giderek daha az kaynakla çalışabilir hale geliyor.
Multimodal AI’nin Geleceği
2024–2026 döneminde multimodal AI “text to image” şeklindeki dar tanımın çok ötesine geçti. Gerçek güç, birden fazla modaliteyi aynı anda anlayan ve bunlar arasında anlam köprüleri kuran modellerde yatıyor.
Önümüzdeki dönemde büyük ihtimalle şu gelişmelere tanıklık edeceğiz: Her fiziksel sensörün, kamera, mikrofon, LiDAR, dokunmatik yüzey, bir AI modeline bağlandığı cihazlar. Uzun süreli video anlama kapasitesinin standart hale gelmesi. Gerçek zamanlı çeviri, yorumlama ve analiz pipeline’larının tek model üzerinde birleşmesi.
RAG mimarileri ile birleştiğinde multimodal modeller, kurumsal bilgi tabanlarını metin + görsel + ses üçgeninde sorgulayabilen sistemler haline gelebilir. Bu, arama motorlarının bile yapısını dönüştürme potansiyeli taşıyor.
Multimodal yapay zeka, yapay zekanın gerçek dünyayla yüzleştiği cephedir. Ve bu cephe, 2026’da her geçen ay genişliyor.
Bu yazıda kullanılan terimler için sözlüğümüze göz atabilirsiniz: LLM nedir?, Transformer nedir?, Embedding nedir?.



