list_altİçindekilerexpand_more
Büyük dil modellerini üretime taşıdığınızda ilk sürpriz gecikme süresidir. Yüksek parametreli bir modelden uzun bir yanıt ürettiriyorsunuz; tokenler tek tek, saniyede 20-30 adet geliyor. GPU’da ağırlıklar yüklü, işlem kapasitesi teoride çok daha yüksek. Peki nerede takılıyor?
Sorun otoregresif yapıda. Transformer tabanlı bir dil modeli her yeni token için tüm ağı baştan sona çalıştırır. 100 tokenlik bir yanıt, 100 ayrı forward pass demektir ve bu geçişler birbirine bağlı olduğundan paralel çalıştırılamaz. 70 milyar parametreli bir modelde her adım, GPU belleğinden gigabaytlarca veri okumak anlamına gelir. GPU çekirdeği kapasitesi ile bellek bant genişliği arasında ciddi bir uçurum vardır; matris çarpmaları her token adımında tam kapasitede çalışmaz, GPU çoğunlukla veriyi bekler. Buna “memory-bandwidth-bound” darboğaz denir. Hesaplama değil, bellek okuma kısıtlayıcıdır.
Rakamlarla somutlaştıralım: bir A100 GPU’nun teorik FP16 kapasitesi 312 TFLOP/s, bellek bant genişliği yaklaşık 2 TB/s’dir. Llama 3 70B, FP16 formatında yaklaşık 140 GB ağırlık içerir; bu kütleyi bant genişliğine böldüğünüzde token başına yaklaşık 70 ms salt veri transfer süresi çıkar. H100 ailesi 3.35 TB/s ile bu sınırı yukarı çeker ama temeli değiştirmez: ağırlıklar ne kadar büyükse token başına maliyet o oranda artar. Bellek okuma verimsizliği gecikmenin asıl kaynağıdır; hesaplama kapasitesini artırmak ya da model boyutunu küçültmek bu sorunu doğrudan çözmez. Speculative Decoding bu boşluktan yararlanmanın bir yoludur.
Speculative Decoding nedir?
Temel fikir 2023’te DeepMind ve Google Research tarafından birbirinden bağımsız yayınlandı. Her iki grup da benzer matematiksel çerçeveye ulaştı; teknik bir süre sonra vLLM ve TensorRT-LLM gibi üretim motorlarının standart bir parçası haline geldi. Bugün üretim ortamında LLM çalıştıran pek çok ekip bu tekniği arka planda zaten kullanıyor.
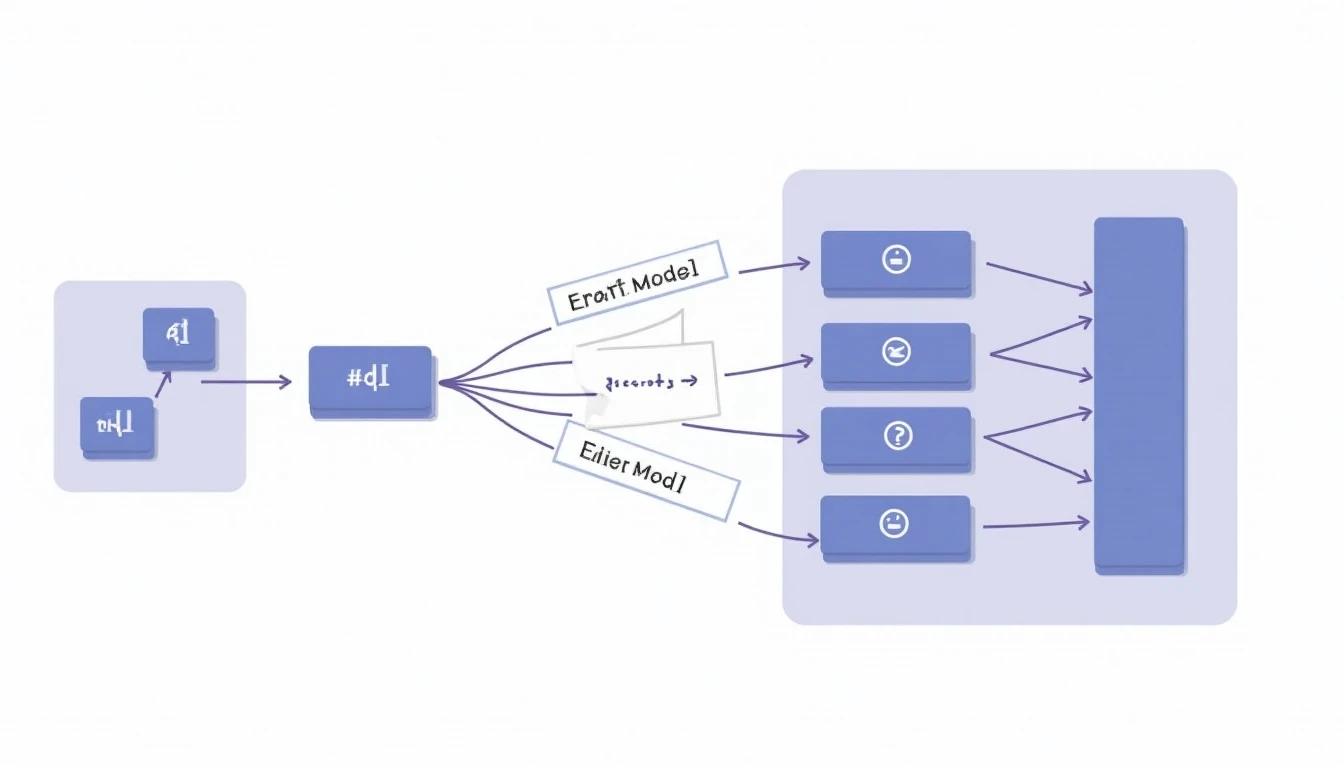
İki model birlikte çalışır: küçük bir “draft” (taslak) model ve büyük bir “target” (hedef) model. Draft model 7 milyar parametreli, hızlı ama daha sınırlı bir modeldir. Target model 70 milyar parametreli, asıl kaliteli çıktıyı üreten modeldir.
Akış şöyle:
- Draft model K adet token üretir. Spekülatif tahmindir; doğru da olabilir yanlış da.
- Target model bu K tokeni ve önceki bağlamı tek bir forward pass ile değerlendirir.
- Target modelin olasılık dağılımları draft modelin tahminleriyle karşılaştırılır.
- Her token kabul ya da reddedilir. Kabul edilenler çıktıya eklenir; ilk reddedilen noktada target modelin dağılımından yeni bir token örneklenir, süreç başa döner.
Önemli olan şu: target modelin kalitesi çıktıda korunur. Süreç deterministik bir reddetme örneklemesi kullandığından çıktı dağılımı, yalnızca target modeli çalıştırmakla matematiksel olarak eşdeğerdir. Hız kazanırsınız, kaliteden ödün vermezsiniz.
Çalışma mekanizması
Acceptance rate (kabul oranı) bu sistemde her şeyi belirler. Draft model target modelin üreteceklerini ne kadar doğru tahmin ederse, tek bir target forward pass’te o kadar çok token onaylanır.
Matematik şöyle işler: x_t tokeni için draft modelin olasılığı q(x_t), target modelin olasılığı p(x_t) olsun. p(x_t) ≥ q(x_t) ise token her koşulda kabul edilir. Aksi halde p(x_t)/q(x_t) olasılıkla kabul edilir, kalan olasılıkla reddedilir. Kabul kriteri basit bir eşik değil, rejection sampling tabanlıdır: kabul ihtimali min(1, p(x)/q(x)) olarak hesaplanır.
Bu ret mekanizması target modelin olasılık dağılımını korur. Draft modelin çıktıları tamamen rastgele bile olsa doğrulama adımı geçerli çıktı üretir; sonuç her zaman target modelin dağılımından örneklenmiş bir dizidir. Draft model kalitesi yalnızca hızı etkiler, çıktının doğruluğunu değil.
İnce ama önemli bir ayrıntı daha var: target model bir draft tokeni reddettiğinde, o pozisyon için kendi üreteceği tokeni zaten hesaplamış olur. Hiçbir forward pass ziyan gitmez; reddedilen taslak döngüyü yavaşlatmaz, yalnızca o noktada zincirlemeyi keser. Her döngüde en az 1, en fazla K+1 token çıktıya eklenir.
Pratikte bu matematiksel garanti çok önemlidir. Bir LLM deployment’ında “hızlandırma tekniği kullandım, ama çıktı kalitesi değişti mi?” sorusu her zaman geçerlidir. Speculative decoding’de bu sorunun cevabı nettir: değişmedi. Kabul/ret örneklemesi tam anlamıyla lossless bir hız optimizasyonudur.
Draft model → [t1, t2, t3, t4] (spekülatif)
Target model → [t1✓, t2✓, t3✗, yeni_t3] (tek forward pass)
Sonuç: [t1, t2, yeni_t3] (2 kabul + 1 yeniden üretim)
K değerinin (literatürde γ olarak da geçer) seçimi pratik bir denge sorunudur. K = 1 ile her döngüde yalnızca tek draft token denenir; overhead yüksek, kazanım düşük kalır. K = 8 ile daha uzun taslaklar denenir ama kabul oranı düşükse çoğu reddedilir ve döngü kısalır. Çoğu uygulama K = 4-5 ile başlayıp kendi iş yüküyle kalibre eder.
Neden hızlanma oluşur?
Her otoregresif adım küçük bir matris çarpmasıdır; GPU büyük bölümünü boşa geçirir. Target modelin tek bir forward pass’te K+1 pozisyonu paralel hesaplaması ise GPU’yu çok daha verimli kullanır.
K+1 pozisyonu aynı anda hesaplamak, K+1 ayrı forward pass’ten daha az bellek bant genişliği tüketir. Ağırlıklar bellekten bir kez okunur, birden fazla token için işlenir.
Bu fark en çok batch size 1, yani tek istek işlendiğinde belirginleşir. Batch size arttığında klasik otoregresif üretim GPU’yu zaten daha iyi doldurur; speculative decoding’in katkısı görece azalır. Bu nedenle teknik özellikle interactive chatbot ve API servislerinde, yani tek kullanıcıya düşük gecikme ile yanıt verilmesi gereken senaryolarda değer üretir.
Beklenen kazanımı kabaca kestirmek de mümkün. Ortalama kabul oranı α, draft token sayısı K ve target modelin draft modele göre maliyet oranı c olsun; teorik hızlanma tahmini:
speedup ≈ (1 - α^(K+1)) / ((1 - α) · (1 + K/c))α = 0.8, K = 4, c = 9 için bu formül yaklaşık 2.5x verir. Kabul oranı 1 olmasa bile kazanç oluşur, çünkü her döngüde target model yine en az 1 token üretir; kabul edilen ekstra tokenler ek maliyet getirmeden gelir.
Acceptance rate birkaç faktöre bağlıdır: iki modelin dağılım yakınlığı, giriş türü ve K değerinin seçimi. Kod tamamlama ve çeviri gibi tahmin edilebilir görevlerde α genellikle 0.85-0.95 bandındadır; dil çok belirleyicidir, küçük model büyüğün kararına yakın kalır. Yaratıcı yazı ve açık uçlu sohbette α 0.6-0.75’e kadar düşebilir. Temperature da işin içindedir: düşük temperature dağılımı keskinleştirir ve kabul oranını yükseltir; yüksek temperature’da tersi geçerlidir. Geniş ölçekli üretim ortamlarında doğal dil üretimi için %70-85 kabul oranı elde edildiği bildirilmektedir; bu da teorik 3-4x hızlanmayı gerçekçi kılar.
Draft model nasıl seçilir?
Draft model seçimi kritik bir tasarım kararıdır. İdeal draft model, target modelle aynı aileden gelen, küçük ama makul doğrulukta bir modeldir. Aile içi küçük modeller büyük modele yakın bir dağılım üretir, bu da kabul oranını yüksek tutar. Llama-3-8B ile Llama-3-70B veya Qwen2.5-7B ile Qwen2.5-72B klasik çiftlerdir.
350M parametreli çok küçük bir model hızlı çalışır ama kabul oranı düşer; çok büyük bir model kendi başına kaynak tüketir. Çoğu üretim kurulumunda target modelin 5-10 katı küçük bir draft model iyi bir denge noktası oluşturur.
Quantized draft model kullanımı pratikte yaygın bir tercihtir. AWQ veya GPTQ ile 4-bit’e sıkıştırılmış Llama-3-8B yaklaşık 5 GB yer kaplar; FP16’daki 16 GB yükü üçte birine indirger. Kabul oranı çoğu durumda FP16 draft ile karşılaştırılabilir düzeyde kalır. vLLM, TensorRT-LLM ve HuggingFace TGI quantized draft modeli destekler; hangi formatın çalıştığını framework dokümantasyonundan doğrulamak gerekir.
Gerçek benchmark’lar
Tekniği ilk sistematik biçimde formüle eden Leviathan ve arkadaşlarının 2023 tarihli makalesi, Chinchilla 70B üzerinde 2.4x token/sn artışı bildirdi. Bu oran, target ve draft maliyetlerinin oranı ile kabul oranına bağlı olduğundan modelden modele değişir.
| Yapılandırma | Standart Decoding (tok/sn) | Speculative Decoding (tok/sn) | Kazanım |
|---|---|---|---|
| Llama-3-70B (tek A100) | ~18 | ~42 | ~2.3x |
| Llama-3-70B + 8B (tek A100) | — | ~38-44 | 2.1-2.4x |
| Gemma 27B + 2B | ~28 | ~62 | ~2.2x |
Benchmark koşulları sonuçları doğrudan etkiler. Tek kullanıcılı veya düşük batch senaryolarında (geliştirici araçları, bireysel chatbot) speculative decoding en yüksek etkiyi gösterir. Aynı GPU üzerinde çalışan 100 eş zamanlı istek varsa batch’leme GPU’yu zaten verimli doldurduğundan etki azalır. Tablodaki rakamlar batch_size=1 veya düşük concurrency koşullarında üretildi; üretim rakamlarınız iş yüküne göre farklılaşır.
Varyantlar ve alternatif yaklaşımlar
Standart speculative decoding üzerine birkaç farklı yöntem geliştirildi.
Medusa: Tek bir büyük model üzerine birden fazla ek “decoding kafası” (head) ekler. Bu kafalar bir sonraki, iki sonraki, üç sonraki token için paralel tahminler üretir. Ayrı bir draft model gerekmez; tek model bellekte tutulur ve birden fazla head ile spekülatif üretim yapılır. Kafalar hedef modelin iç temsillerini kullandığından yüksek acceptance rate elde etmek görece kolaydır. Dikkat edilmesi gereken nokta: Medusa kullanmak için modeli fine-tune etmek gerekir; ek kafalar mevcut ağırlıklara eklenir ve bu kafalar için ayrı bir eğitim adımı zorunludur. Off-the-shelf bir model çiftinin hemen kullanılabildiği klasik speculative decoding’den bu yönüyle ayrılır. Medusa-2, kafalara öğretilebilir katmanlar ekleyerek kabul oranını artırmayı hedefler.
EAGLE: Draft modeli olarak ana modelin özellik vektörlerini girdi alan daha küçük bir otoregresif model kullanır. Ana modelin gizli durumlarına erişim, draft kalitesini artırır. EAGLE2, bu yaklaşımı daha gelişmiş bir draft ağıyla genişletti ve 2024 benchmark’larında hem Medusa hem de vanilla speculative decoding üzerinde daha iyi sonuçlar verdi.
Hydra: Medusa’nın bir uzantısıdır; kabul kriterini daha agresif biçimde optimize eder ve ağaç biçiminde token alternatifleri değerlendirir.
Lookahead Decoding: Jacobi iteration kavramından esinlenir. Paralel n-gram zincirleri oluşturulur; örtüşen kısımlar doğrulama aşamasında kullanılır. Ek model gerekmez; tek model içinde çoklu yol keşfi yapılır. Sözlük büyüklüğü ve içerik türüne göre değişken performans gösterir.
Self-Speculative Decoding: Modelin erken katmanları tahmin üretir, son katmanlar doğrular. Tek model iki rol üstlenir; ek model yüklenmez, bellek ayak izi değişmez. Kazanım oranı ayrı draft modele göre daha mütevazı kalır.
SpecInfer ve REST: Ağaç yapısı kullanır. Draft model olası devam yollarının ağacını üretir; target model bu ağacı paralel tek pass ile değerlendirir. Yüksek acceptance rate potansiyeli vardır ama uygulama karmaşıklığı artar.
Bu varyantların hangisinin seçileceği büyük ölçüde operasyonel kısıtlamalara bağlıdır. İkinci bir model yükleyemiyorsanız Medusa veya Self-Speculative daha uygun olur. Mevcut bir 70B modeliniz varsa ve küçük bir Llama modelini ekleyebiliyorsanız standart speculative decoding en az operasyonel sürtüşmeyle en iyi başlangıç noktasıdır. Hangi yaklaşımın daha iyi çalıştığı model ailesine ve kullanım senaryosuna göre değişir; karar vermeden önce kendi veri setinizle kısa bir benchmark koşmak faydalı olur.
Üretimde kullanım: vLLM entegrasyonu
vLLM speculative decoding’i 0.4 sürümünden bu yana doğrudan destekler. Komut satırından birkaç ek parametre yeterlidir:
vllm serve meta-llama/Llama-3.1-70B-Instruct \
--speculative-model meta-llama/Llama-3.2-1B-Instruct \
--num-speculative-tokens 570B model target, 1B model draft rolünü üstlenir. --num-speculative-tokens her döngüde kaç spekülatif token üretileceğini belirler. Düşük K daha az risk ama daha az kazanım; yüksek K, acceptance rate yüksek senaryolarda büyük kazanım, düşük acceptance rate senaryolarda overhead getirir. 3-5 arası değerler çoğu iş yükü için iyi bir başlangıç noktasıdır.
Aynı yapılandırma Python API’sinden de kurulabilir:
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3.1-70B-Instruct",
speculative_model="meta-llama/Llama-3.1-8B-Instruct",
num_speculative_tokens=4,
speculative_draft_tensor_parallel_size=1,
)
params = SamplingParams(temperature=0.2, max_tokens=512)
outputs = llm.generate(["Transformer mimarisinde KV cache nedir?"], params)
print(outputs[0].outputs[0].text)HuggingFace Transformers’da aynı işlev assistant_model parametresi üzerinden yürür:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
draft_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct",
torch_dtype=torch.float16, device_map="cuda",
)
target_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-70B-Instruct",
torch_dtype=torch.float16, device_map="cuda",
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-70B-Instruct")
inputs = tokenizer("Speculative decoding nasıl çalışır?", return_tensors="pt").to("cuda")
outputs = target_model.generate(**inputs, assistant_model=draft_model, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Draft ve target modelin aynı aileden gelmesi acceptance rate için kritiktir. Llama-3.1-70B ile Llama-3.2-1B aynı tokenizer ve benzer eğitim dağılımını paylaştığından iyi bir eşleşme oluşturur. Farklı mimariden gelen bir draft model düşük kabul oranıyla net kazanım üretemeyebilir.
TensorRT-LLM ve Google Cloud AI Platform da bu optimizasyonu kendi altyapılarına ekledi. Açık kaynak ve kapalı kaynak inference motorlarının büyük bölümünde artık standart bir seçenek olarak yer alıyor.
Kazanım uzun çıktılarda daha belirgindir: yüzlerce token uzunluğundaki yanıtlarda veya döküman özetlemede kümülatif hız artışı gerçekten hissedilir. Kısa yanıtlarda overhead bazen bu avantajı ezer.
vLLM ayrıca --speculative-draft-tensor-parallel-size parametresiyle draft modelin kaç GPU’da paralel çalışacağını ayrıca yapılandırmanıza olanak tanır. Büyük kurulumlar için draft ve target modeli farklı GPU gruplarına dağıtmak da mümkündür; throughput optimizasyonu ile gecikme azaltma böylece ayrı ayrı ayarlanabilir.
Diğer optimizasyon teknikleriyle ilişkisi
Speculative decoding ve quantization farklı boyutlarda etkir, birbirini dışlamaz. Quantization ağırlıkların hassasiyetini düşürerek bellek kullanımını azaltır ve bazı işlemleri hızlandırır. Speculative decoding ise çıkarım döngüsünün mimarisini değiştirir. İkisi birlikte kullanılabilir: quantize edilmiş küçük bir draft model spekülatif üretimde verimli çalışır.
KV Cache ile ilişki tamamlayıcıdır. KV Cache, attention hesaplamalarını saklayarak tekrar işlemeyi önler. Speculative decoding bu altyapının üzerinde çalışır; doğrulama sırasında draft tokenlerin KV cache girişleri dikkatle yönetilmelidir. vLLM gibi modern inference motorları bunu otomatik yapar.
Continuous Batching farklı bir şeyi optimize eder: birden fazla istek arasında GPU’nun boş kalmamasını hedefler. Speculative decoding ise tek bir istek içindeki token üretimini hızlandırır; ikisi aynı anda etkin olabilir.
Akıl yürüten modeller gibi uzun düşünce zinciri gerektiren sistemlerde speculative decoding işe yarar. Yüzlerce token uzunluğundaki chain-of-thought çıktılarında acceptance rate yüksek kalabilir ve kümülatif kazanım belirginleşir.
Bir noktanın altını çizmek gerekir: quantization model ağırlıklarını kalıcı olarak değiştirir, fine-tuning üzerinde belirli etkileri olabilir. Speculative decoding ise ağırlıklara hiç dokunmaz; yalnızca inference döngüsünü değiştirir. Bu açıdan deployment esnekliği sunar: mevcut bir modeli yeniden eğitmeden, ağırlık formatını değiştirmeden üretim gecikmelerini düşürmek mümkündür.
Sınırlamalar
Bazı senaryolarda speculative decoding beklenen kazanımı üretemez.
Düşük acceptance rate: Draft model sistematik olarak yanlış tahmin ediyorsa her döngüde az token kabul edilir. Her döngü hem draft hem target forward pass maliyeti taşır ama çok az token çıktıya eklenir; standart otoregresif üretimden yavaş çalışabilir. Yaratıcı yazı ve yüksek temperature bu riski büyütür; α 0.6’nın altına indiğinde toplam maliyet bazen standart decoding’i geçer.
İki model belleği: Her iki modelin GPU belleğine yüklenmesi gerekir. 70B modeli güçlükle tutan bir kurulumda 7B’lik draft için yer bulmak güçleşir. 1B-3B arası küçük bir draft model yaygın çözümdür; quantize draft modeller bellek baskısını daha da azaltır.
Tokenizer uyumluluğu: Draft ve target modelin aynı tokenizer’ı kullanması şarttır. Olasılık dağılımlarını karşılaştırmak için aynı kelime dağarcığı gerekir; farklı tokenizer mimarisine sahip iki model pratikte birleştirilemez.
Kısa yanıtlar: Speculative decoding uzun çıktılarda en fazla kazanımı üretir. Birkaç kelimelik yanıtlarda döngünün maliyeti net hız artışını ortadan kaldırabilir.
Streaming gecikmesi: Teknik throughput’u artırır ama ilk token gecikme süresini (TTFT) doğrudan iyileştirmez. Birinci token için draft döngüsü olsa bile target modelin forward pass’i zorunludur.
Yüksek eş zamanlı yük ve çok GPU’lu dağıtımlar: vLLM benzeri sunucular yüksek batch boyutlarıyla GPU’yu zaten dolu tutuyorsa speculative decoding ek karmaşıklık katar, kazanım marjinalleşir. Draft ve target farklı GPU’lara dağıtıldığında iletişim overhead’i devreye girer; tek node içinde NVLink ile bağlı GPU’lar bu maliyeti küçültür, farklı node’lara taşındığında ağ gecikmesi kazanımı önemli ölçüde yiyebilir.
Üretime almadan önce hedef görev üzerinde acceptance rate ölçümü yapmak yerinde olur. Kendi kullanım senaryonuzdan birkaç yüz istek alıp draft tokenlerin kaçının kabul edildiğini loglamak yeterlidir; vLLM bu metriği speculative_tokens_accepted alanında raporlar, bu sayıyı num_speculative_tokens ile bölünce anlık α elde edilir. Kabul oranı %50’nin altında kalıyorsa knowledge distillation gibi alternatifler daha verimli bir başlangıç noktası olabilir.
Üretim altyapısındaki yeri
Speculative decoding LLM gecikme sorununa somut bir yanıt sunar: çıktı kalitesini, ağırlıklarını ya da fine-tuning’ini değiştirmeden, çıkarım mimarisindeki paralellikten kazanım elde eder. 2024 sonrasında vLLM ve TensorRT-LLM’de olgunlaştı, birkaç parametre ile etkinleştirilebilir hale geldi.
LLM’in nasıl çalıştığını ve vLLM’in inference motoru mimarisini anlayanlar için speculative decoding, bu parçaların üzerine oturan bir hız katmanıdır. Kaliteden taviz vermeden gecikme sürelerini kısaltmak isteyenler için somut bir seçenektir.