list_altİçindekilerexpand_more
- 01Kimi K2.6: Moonshot AI’nın Mühendislik Başarısı
- 02Kimi K2.6 Benchmark Sonuçları
- 03Qwen3.6 Plus: Alibaba’nın Stratejik Hamlesi
- 04Qwen3.6 Plus’ın Güçlü Yönleri
- 05İkisi Arasındaki Temel Fark: Ne Zaman Hangisini Kullanmalı?
- 06Yerel Kurulum: Qwen3.6 Plus ile Başlangıç
- 07API Entegrasyonu: Maliyet Karşılaştırması
- 08r/LocalLLaMA Tartışmalarının Özeti
- 09Güvenlik ve Veri Gizliliği Değerlendirmesi
- 10Türkiye’deki Geliştirici İçin Pratik Değerlendirme
- 11Rakip Manzarası: Bu Modeller Nerede Duruyor?
- 12Sonuç
- 13İlgili Karşılaştırmalar
Altı ay önce “açık kaynak modeller kapalı frontier modellerin yüzde seksenine ulaşmış” diyorduk. Mayıs 2026 itibarıyla bu mesafe kapandı, en azından kodlama görevlerinde. Moonshot AI’nin Kimi K2.6’sı SWE-Bench Verified’da %71.2 ile Claude Opus 4.7’nin hemen gerisine yerleşirken, Alibaba’nın Qwen3.6 Plus’ı Terminal-Bench 2.0’da GPT-5.5’i geride bıraktı; bu modelleri kapalı frontier modelleriyle kıyaslamak için AI model karşılaştırma rehberimize bakabilirsiniz. Bu iki model r/LocalLLaMA’yı alevlendirdi, birden fazla startup’ın infrastructure kararını değiştirdi ve “yerel modelle ne kadar gidebiliriz?” sorusunu yeniden masaya taşıdı.
Bu yazıda her iki modeli benchmark verisi, gerçek kullanım senaryoları ve Türk geliştirici perspektifinden karşılaştıracağız.
 Kimi K2.6 ve Qwen3.6 Plus, kapalı frontier modellere en yaklaşan açık ağırlıklı rakipler haline geldi.
Kimi K2.6 ve Qwen3.6 Plus, kapalı frontier modellere en yaklaşan açık ağırlıklı rakipler haline geldi.
Kimi K2.6: Moonshot AI’nın Mühendislik Başarısı
Çin merkezli Moonshot AI, Kimi K2.6’yı Mayıs 2026’nın ikinci haftasında yayınladı. Model açık ağırlıklı olarak indirilebiliyor ve ticari kullanım için lisanslı. İşte teknik detaylar:
- Parametre sayısı: 1 trilyon (toplam), aktif kullanım sırasında ~280 milyar (MoE)
- Mimari: Mixture of Experts, 256 expert katmanı, her token’da 8’i aktive
- Context window: 256K token
- Eğitim verisi: Mayıs 2026 kesim tarihi
- Lisans: Apache 2.0 (ticari kullanıma açık)
MoE mimarisi bu modelin neden bu kadar dikkat çekici olduğunu açıklıyor: 1 trilyon parametreye sahip olmasına rağmen, her çıkarım adımında yalnızca yaklaşık 280 milyar parametre aktive oluyor. Bu sayede GPT-4o düzeyinde bir yoğun model kadar hesaplama gücü gerektiriyor ama teorik kapasite çok daha yüksek.
Kimi K2.6 Benchmark Sonuçları
| Benchmark | Kimi K2.6 | Claude Opus 4.7 | GPT-5.5 | Qwen3.6 Plus |
|---|---|---|---|---|
| SWE-Bench Verified | 71.2% | 73.8% | 68.9% | 64.1% |
| Terminal-Bench 2.0 | 68.4% | 70.1% | 65.2% | 72.3% |
| HumanEval+ | 89.1% | 91.4% | 88.7% | 87.9% |
| MATH-500 | 84.3% | 87.2% | 85.1% | 86.8% |
| MMLU Pro | 79.6% | 82.4% | 81.3% | 80.9% |
Tablo: Mayıs 2026 kamuya açık benchmark sonuçları. SWE-Bench ve Terminal-Bench kodlama odaklı.
SWE-Bench Verified, gerçek GitHub reposundan alınan issue’ları çözme yeteneğini ölçüyor. Kimi K2.6’nın %71.2’si, altı ay öncesinin en iyi kapalı modelleriyle yarışıyor.
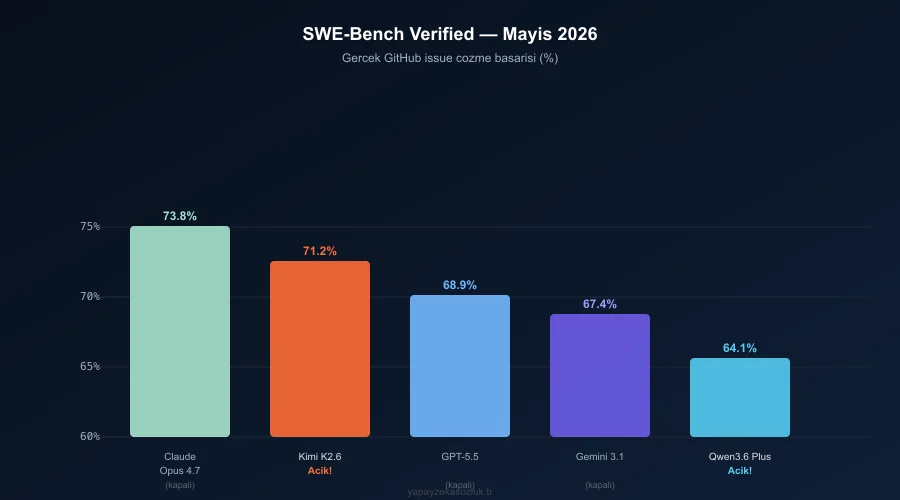 Mayıs 2026 kodlama benchmark karşılaştırması: Kimi K2.6 kapalı frontier modellere bu kadar yaklaşan ilk açık ağırlıklı model.
Mayıs 2026 kodlama benchmark karşılaştırması: Kimi K2.6 kapalı frontier modellere bu kadar yaklaşan ilk açık ağırlıklı model.
Qwen3.6 Plus: Alibaba’nın Stratejik Hamlesi
Alibaba’nın Qwen ailesi her yeni sürümde biraz daha sürpriz yapıyor. Qwen3.6 Plus’ın öne çıkan tarafı Terminal-Bench 2.0’daki performansı, komut satırı yoğun görevlerde GPT-5.5’i geçmesi. Bu test, shell komutlarını doğru sırayla çalıştırma, hata mesajlarını yorumlama ve çok adımlı bash scriptleri yazma gibi DevOps odaklı yetenekleri ölçüyor.
Qwen3.6 Plus teknik özellikleri:
- Parametre sayısı: 72 milyar (yoğun mimari, MoE değil)
- Context window: 128K token
- Diller: 119 dil (Türkçe dahil, ama Türkçe performansı Çince/İngilizce kadar güçlü değil)
- Lisans: Qwen Lisansı (ticari kullanım için başvuru gerekiyor, 100M+ DAU sınırı)
- Kuantizasyon: 4-bit ve 8-bit sürümleri mevcut
72 milyar parametre, Kimi K2.6’ya göre çok daha yönetilebilir, tek bir A100 GPU’ya 4-bit kuantizasyonla sığabiliyor. Bu onu local deployment için K2.6’dan çok daha pratik kılıyor.
Qwen3.6 Plus’ın Güçlü Yönleri
# Qwen3.6 Plus ile bir DevOps görevi örneği
# Terminal-Bench 2.0'da test edilen türden bir görev
import subprocess
def deploy_check():
"""Check if services are running and restart if needed."""
services = ['nginx', 'postgresql', 'redis']
for service in services:
result = subprocess.run(
['systemctl', 'is-active', service],
capture_output=True, text=True
)
if result.stdout.strip() != 'active':
print(f"{service} durdu, yeniden başlatılıyor...")
subprocess.run(['systemctl', 'restart', service])
print(f"{service} yeniden başlatıldı.")
else:
print(f"{service} çalışıyor.")
deploy_check()Qwen3.6 Plus bu tür shell-yoğun, araç çağırma ağırlıklı görevlerde özellikle iyi performans gösteriyor.
İkisi Arasındaki Temel Fark: Ne Zaman Hangisini Kullanmalı?
Bu iki modeli seçmek için doğru soru “hangisi daha iyi?” değil, “hangi görev için, hangi altyapıyla?”
Kimi K2.6’yı seç eğer:
- Karmaşık, çok dosyalı kod tabanları üzerinde çalışıyorsan (256K context)
- Tek seferlik büyük refactor ya da kod analizi görevlerin varsa
- API üzerinden kullanıyorsan (Moonshot AI API, OpenRouter, Replicate)
- SWE-Bench düzeyinde problem çözme yeteneği kritikse
Qwen3.6 Plus’ı seç eğer:
- Yerel inference istiyorsan (72B 4-bit → ~45GB VRAM)
- Terminal/shell ağırlıklı DevOps veya SRE iş akışların varsa
- Tekrarlı, yüksek hacimli görevlerin var ve maliyet önemliyse
- CI/CD pipeline’ına gömülü bir AI asistanı istiyorsan
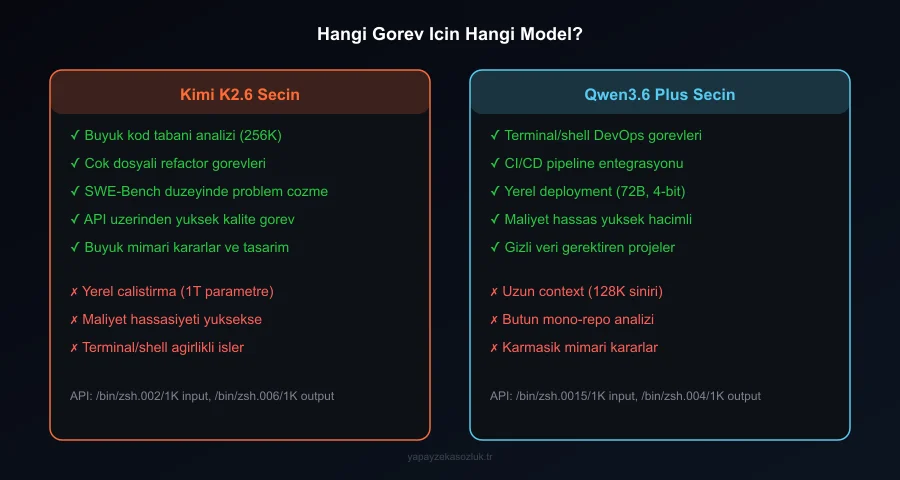 İki modelin güçlü tarafları: Kimi K2.6 derin kod analizi için, Qwen3.6 Plus yerel DevOps görevleri için.
İki modelin güçlü tarafları: Kimi K2.6 derin kod analizi için, Qwen3.6 Plus yerel DevOps görevleri için.
Yerel Kurulum: Qwen3.6 Plus ile Başlangıç
Qwen3.6 Plus’ı Ollama üzerinden çalıştırmak birkaç komut meselesi:
# Ollama kurulumu (zaten kuruluysa atla)
curl -fsSL https://ollama.ai/install.sh | sh
# Qwen3.6 Plus modelini indir (45GB, sabırlı ol)
ollama pull qwen3.6-plus:q4_k_m
# Temel test
ollama run qwen3.6-plus:q4_k_m "Aşağıdaki Python kodundaki hatayı bul:"
# API modu (OpenAI uyumlu)
OLLAMA_HOST=0.0.0.0 ollama serveMinimum donanım gereksinimleri Qwen3.6 Plus için:
- 4-bit (Q4_K_M): 48GB RAM veya 2x24GB GPU (RTX 4090 çifti)
- 8-bit (Q8_0): 80GB RAM veya 2x40GB GPU (A100 çifti)
- Full precision: 144GB RAM veya 4x40GB GPU
Gerçekçi olmak gerekirse, Qwen3.6 Plus’ı yerel çalıştırmak için ciddi donanım gerekiyor. 4-bit kuantize bile 48GB RAM istediğinden, çoğu geliştirici API yolunu tercih edecek.
API Entegrasyonu: Maliyet Karşılaştırması
from openai import OpenAI
# Kimi K2.6 (Moonshot AI API)
kimi_client = OpenAI(
api_key="moonshot-api-key",
base_url="https://api.moonshot.cn/v1"
)
response = kimi_client.chat.completions.create(
model="kimi-k2-6",
messages=[
{"role": "user", "content": "Bu Python kodunu refactor et ve test ekle:"}
],
max_tokens=4096
)
# Maliyet: ~$0.002/1K token input, $0.006/1K token output
# (Mayıs 2026 itibarıyla OpenRouter fiyatı)# Qwen3.6 Plus (Alibaba Cloud)
qwen_client = OpenAI(
api_key="alibaba-cloud-key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
response = qwen_client.chat.completions.create(
model="qwen3.6-plus",
messages=[...],
max_tokens=4096
)
# Maliyet: ~$0.0015/1K token input, $0.004/1K token output
# (Yerli AI modellerinde %30-40 daha ucuz)Fiyat/performans açısından Qwen3.6 Plus avantajlı çıkıyor: benzer görevlerde yaklaşık %30-40 daha ucuz, terminal görevlerinde K2.6’yı bile geride bırakıyor.
r/LocalLLaMA Tartışmalarının Özeti
Bu iki model r/LocalLLaMA ve r/MachineLearning’de yüzlerce yorumla karşılandı. Öne çıkan görüşler:
“Kimi K2.6 ile bir ay önce GPT-5.5 ile yaptığım kodlama görevinin aynısını yaptım. Fark anlayamadım. API fiyatı ise yarısı.”, u/dev_practitioner
“Qwen3.6 Plus’ı CI pipeline’ıma gömdüm. Her PR’da diff analizi ve güvenlik taraması yapıyor. Ayda $40 harcıyorum, çok daha pahalı kapalı modeller yerine.”, u/sre_hacks
“256K context ciddi bir fark yaratıyor. Büyük mono-repo’yu K2.6’ya besleyebiliyorum, GPT-5.5’te context limit doluyordu.”, u/backend_arch
Eleştiriler de var:
“Qwen3.6’nın Türkçe output kalitesi çok değişken. İngilizce sorsan iyi cevap veriyor, Türkçe sorsan bazen dönüşümlü kod yazıyor.”, u/turkce_dev
Bu gözlem kritik: her iki model de Türkçe prompt’ta İngilizce kod output vermeye eğilimli. Türkçe iş mantığı açıklamaları için İngilizce prompt yazmak hâlâ daha güvenli.
 Qwen3.6 Plus yerel çalıştırma: 4-bit kuantizasyonla 48GB RAM yeterli, ama API yolu çoğu geliştirici için daha pratik.
Qwen3.6 Plus yerel çalıştırma: 4-bit kuantizasyonla 48GB RAM yeterli, ama API yolu çoğu geliştirici için daha pratik.
Güvenlik ve Veri Gizliliği Değerlendirmesi
Çin menşeli modeller söz konusu olduğunda veri gizliliği sorusu kaçınılmaz. İki farklı senaryo var:
API kullanımında: Verileriniz Moonshot AI veya Alibaba sunucularına gidiyor. İkisi de AB GDPR uyumunu iddia ediyor, ancak bağımsız denetim sertifikaları henüz kamuya açık değil. Şirket verisi veya müşteri PII içeren kod tabanlarını bu API’lere gönderirken dikkatli olun.
Yerel çalıştırmada: Ağırlıklar bir kez indirildikten sonra tamamen yerel inference mümkün. Özellikle finans, sağlık veya kamu gibi regüle sektörlerde bu büyük bir avantaj.
Pratik öneri: hassas veri yoksa API, hassas veri varsa yerel deployment.
Türkiye’deki Geliştirici İçin Pratik Değerlendirme
Türk geliştiriciler için bu modellerin gerçek değeri nerede?
Freelance geliştirici: Qwen3.6 Plus API’si, aylık birkaç dolar maliyetle Claude Opus kalitesine yakın kodlama yardımı sağlıyor. Özellikle rutin CRUD ve API entegrasyon görevleri için değişim noktasına yaklaştı.
Startup geliştirme ekibi: Kimi K2.6’nın 256K context’i, büyük eski kod tabanlarını (“legacy” sistemi) refactor ederken tüm dosyaları aynı anda contexte almayı mümkün kılıyor. Bu büyük proje migrasyonlarında ciddi bir zaman tasarrufu.
SaaS ürün geliştirici: CI/CD’ye gömülü Qwen3.6 Plus, her commit’te otomatik code review ve güvenlik taraması yapabilir. Aylık maliyet bir junior geliştirici saatinin bir kısmı.
Veri bilimci: K2.6’nın güçlü matematik sonuçları (MATH-500’de %84.3) veri analizi betikleri ve istatistik kodu için onu ilginç bir seçenek yapıyor.
Dikkat edilmesi gereken noktalar:
- Her iki modelin de Türkçe output kalitesi tutarsız, kritik belgeler için doğrulama şart
- Kimi K2.6 context sınırını verimli kullanmak için uzun prompt yazma becerisi gerektiriyor
- Qwen3.6 Plus’ın ticari lisansı 100M+ DAU üzeri için ayrı anlaşma istiyor
Rakip Manzarası: Bu Modeller Nerede Duruyor?
Bu iki modelin ortaya çıkmasıyla 2026 ortasında açık ağırlıklı model manzarası şöyle görünüyor:
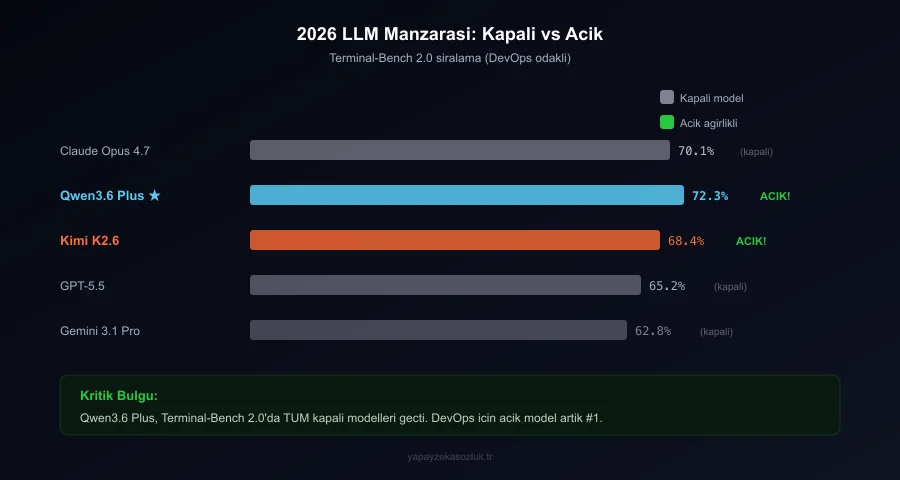
Kodlama ağırlıklı sıralama (SWE-Bench Verified):
- Claude Opus 4.7, %73.8 (kapalı, en pahalı)
- Kimi K2.6, %71.2 (açık ağırlıklı, MoE)
- GPT-5.5, %68.9 (kapalı, orta fiyat)
- Gemini 3.1 Pro, %67.4 (kapalı)
- Qwen3.6 Plus, %64.1 (açık ağırlıklı, 72B)
Terminal/shell ağırlıklı sıralama (Terminal-Bench 2.0):
- Claude Opus 4.7, %70.1
- Qwen3.6 Plus, %72.3 (bu benchmark’ta lider!)
- Kimi K2.6, %68.4
- GPT-5.5, %65.2
Terminal-Bench 2.0’da Qwen3.6 Plus’ın liderliği dikkat çekici. Bu, shell komutları ve DevOps görevleri için kapalı modelleri bile geride bırakabilen bir açık ağırlıklı modelin artık var olduğu anlamına geliyor.
 2026 açık ağırlıklı model manzarası: Kimi K2.6 ve Qwen3.6, kapalı frontier modellere gerçek bir rakip sunuyor.
2026 açık ağırlıklı model manzarası: Kimi K2.6 ve Qwen3.6, kapalı frontier modellere gerçek bir rakip sunuyor.
Sonuç
Kimi K2.6 ve Qwen3.6 Plus, “açık kaynak modeller asla kapalı modellere yetişemez” söylemini aktif olarak yanlışlıyor. Bu iki model yanlışlığı sadece teorik olarak değil, SWE-Bench ve Terminal-Bench gibi pratik benchmark’larda da kanıtlıyor.
Türk geliştirici perspektifinden bakıldığında şunlar kesin:
-
Rutin kodlama görevleri için maliyet avantajı gerçek: Özellikle Qwen3.6 Plus API’si, Claude Opus kalitesinin %80’ini üçte bir fiyatına sunuyor.
-
Yerel deployment artık ciddi bir seçenek: DevOps ağırlıklı iş yükler için Qwen3.6 Plus’ı yerel çalıştırmak, veri gizliliği gereksinimleri olan projelerde kapalı API’den vazgeçmeyi mümkün kılıyor.
-
256K context gerçekten fark yaratıyor: Büyük kod tabanlarıyla çalışan geliştiriciler için Kimi K2.6’nın bu özelliği teknik seçimi sade kılıyor.
-
Türkçe hâlâ zayıf halka: Her iki model de Türkçe prompt ve output kalitesinde tutarsız. Türkçe belgeleme veya kullanıcı iletişimi gerektiren projelerde Claude veya GPT-5.5 hâlâ daha güvenli.
Bu modeller “kapalı modeller yok olsun” demek değil, ama “her görev için en pahalı kapalı modeli kullanmak zorunda değilim” demek için artık yeterince iyi bir neden var.
İlgili Karşılaştırmalar
- Karşılaştırma sayfalarına gözat — tüm yapay zeka modeli ve aracı karşılaştırmalarımız



