GPT-4o bazen beklenmedik kadar yavaş gelir. Kısa bir kod parçası için bile birkaç saniye geçebilir. Bu gecikmenin arkasında yatan neden çoğunlukla GPU’nun yetersizliği değil, transformer mimarisinin temel bir kısıtıdır: her token tek başına üretilmek zorunda.
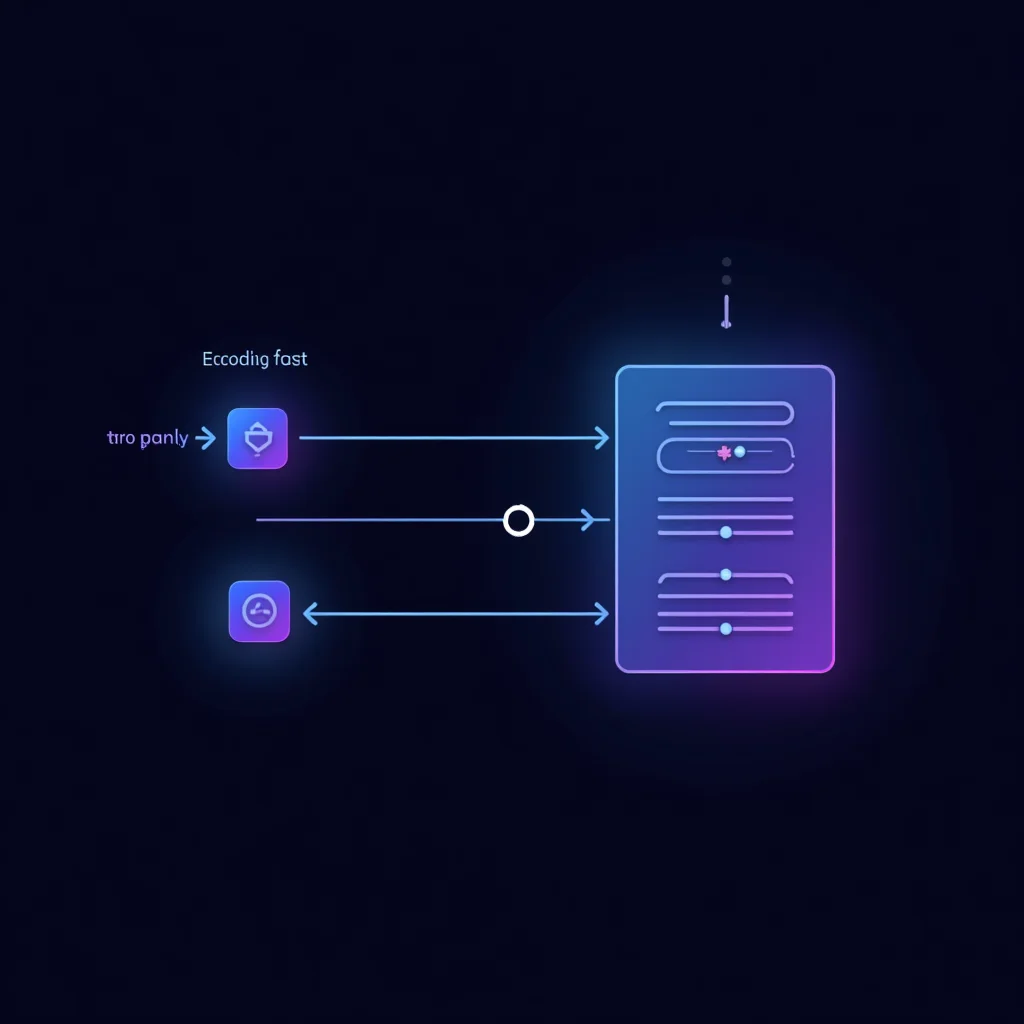
Speculative decoding bu kısıtı kurnaz bir işbölümüyle aşar. Küçük, hızlı bir model birkaç token önerir; büyük model bu önerileri tek seferde kontrol eder. Aynı büyük model kalitesinde, iki ila dört kat daha yüksek throughput mümkün olur.
Teknik 2023’te Google DeepMind ve Stanford’dan iki bağımsız araştırma grubu tarafından eş zamanlı olarak yayımlandı. O tarihten bu yana vLLM, TensorRT-LLM ve HuggingFace Transformers başta olmak üzere tüm büyük çıkarım çerçeveleri yerel destek ekledi. Bugün production ortamında LLM çalıştıran pek çok ekip bu tekniği arka planda zaten kullanıyor.
Autoregressive Üretimin Darboğazı
Transformer tabanlı bir dil modeli token üretirken her adımda tam bir forward pass çalıştırır. 100 token’lık yanıt için 100 ayrı forward pass anlamına gelir; bu geçişler birbirine bağlı olduğundan paralel çalıştırılamaz.
GPU’nun işlem kapasitesi bu durumda asıl kısıtlayıcı faktör değildir. Gerçek darboğaz bellek bant genişliğidir. Her forward pass’te model ağırlıklarının tamamı GPU VRAM’inden hesaplama birimlerine aktarılır. Llama 3 70B gibi büyük modeller FP16 formatında 140 GB ağırlık içerir; bu kütleyi her token için taşımak ciddi bir bant genişliği faturasına yol açar.
Hesap makinesi analojisi şöyle: milyon işlem yapabilen biri, hesap makinesi dışarıda bırakılmış 100 sayıyı sırayla toplayamaz çünkü her toplama için kutunun başına gidip dönmesi gerekir. GPU da her token için ağırlıkları VRAM’den çekmeye gider gelir.
Model büyüdükçe sistem compute-bound değil, memory-bandwidth-bound kalır. Speculative decoding tam bu noktaya dokunuyor.
A100 GPU’sunun bellek bant genişliği yaklaşık 2 TB/s. Llama 3 70B FP16 formatında 140 GB ağırlık içeriyor; bant genişliğini bölünce her token için yaklaşık 70ms salt transfer süresi çıkıyor. Büyük matris çarpmalarının gecikmesi buna ayrıca ekleniyor. H100 ailesi 3.35 TB/s ile bu sınırı yukarı çekiyor, ama temeli değiştirmiyor: ağırlıklar ne kadar büyükse, per-token maliyet de o oranda artıyor.
Speculative Decoding Nasıl Çalışır?
Draft aşaması: Küçük bir “taslak model” (draft model), γ adet token hızla üretir. Bu model büyük modele kıyasla çok daha az parametre içerdiğinden forward pass’i ucuzdur. Örneğin Llama 3 8B, Llama 3 70B için bir draft model olarak kullanılabilir; bant genişliği maliyeti yaklaşık 9 kat daha düşüktür.
Verify aşaması: Büyük model (verifier), draft token’larını ve mevcut bağlamı alıp γ+1 token için tek bir forward pass çalıştırır. Paralel dikkat mekanizması bu geçişte γ+1 token’ın logit’lerini bir kerede üretir. Her draft token, büyük modelin ürettiği logit’lerle karşılaştırılır; istatistiksel kritere uymayan ilk noktada zincir kırılır.
Kabul kriteri basit kabul/red değil, rejection sampling tabanlıdır. Draft modelin olasılığı q(x), büyük modelin olasılığı p(x) için kabul ihtimali min(1, p(x)/q(x)) olarak hesaplanır. Bu formül büyük modelin çıktı dağılımını korur; büyük model kalitesinden ödün verilmez.
γ değeri seçimi pratik bir parametre dengesidir. γ = 1 ile her döngüde yalnızca 1 draft token deneniyor; overhead yüksek, kazanım düşük. γ = 8 ile daha uzun taslaklar deniyor, ama düşük acceptance rate durumunda çoğu reddediliyor ve döngü kısalıyor. Çoğu uygulama γ = 4-5 ile başlayıp kendi workload’larıyla kalibre ediyor. Büyük model bir draft token’ı reddettiğinde o pozisyon için kendi ürettiği token’ı zaten hesaplamış oluyor. Hiçbir forward pass ziyan gitmiyor; reddedilen taslak döngüyü yavaşlatmıyor, sadece o noktada zincirlemeyi kesiyor.
Pratikte ne olur? Birkaç token kabul edilir, biri reddedilir; reddedilen noktada büyük modelin ürettiği token alınır ve döngü baştan başlar. Her döngüde en az 1, en fazla γ+1 token çıkarılır. Ortalama kabul oranı yüksek olduğunda etkin çıktı hızı belirgin artış gösterir.
Draft Model Nasıl Seçilir?
Draft ve verifier aynı tokenizer’ı paylaşmalıdır; farklı vocab kullanan iki model birlikte çalışmaz. Aile içi küçük modeller genellikle büyük modele yakın bir dağılım üretir, bu da acceptance rate’i yüksek tutar. Llama-3-8B ile Llama-3-70B veya Qwen2.5-7B ile Qwen2.5-72B klasik çiftlerdir.
Parametre farkı için 5-10x arası iyi çalışır. Draft model çok küçük olursa acceptance rate düşer; çok büyük olursa maliyet avantajı azalır.
Ayrı bir draft modele gerek duymak istemiyorsanız self-speculative varyantına bakabilirsiniz: tek modelin ara katmanlarından erken çıkışla taslak üretmek mümkün. Ek VRAM gerektirmez ama kazanım oranı da daha mütevazı kalır.
Quantized draft model kullanımı pratikte yaygın bir tercih. AWQ veya GPTQ ile 4-bit’e sıkıştırılmış Llama-3-8B yaklaşık 5 GB yer kaplar; FP16’daki 16 GB yükü üçte birine indirger. Kabul oranı çoğu durumda FP16 draft ile karşılaştırılabilir düzeyde kalır. vLLM, TensorRT-LLM ve HuggingFace TGI quantized draft modeli destekler; hangi formatın işe yarayacağını framework dokümantasyonundan doğrulamak gerekir.
Token Acceptance Rate ve Gerçek Speedup
Ortalama token kabul oranı α olsun; γ draft token denensin; büyük modelin maliyeti küçüğe kıyasla c kat olsun. Theorik speedup tahmini:
speedup ≈ (1 - α^(γ+1)) / ((1 - α) · (1 + γ/c))α = 0.8, γ = 4, c = 9 için bu formül yaklaşık 2.5x verir. Kabul oranı 1 olmadığında bile neden kazanç var? Çünkü her döngüde büyük model yine de en az 1 token çıkarıyor; kabul edilen ekstra token’lar ise bedavaya geliyor.
Acceptance rate göreve göre önemli ölçüde değişir. Kod tamamlama ve çeviri gibi tahmin edilebilir görevlerde α genellikle 0.85-0.95 bandındadır; dil çok belirleyici, küçük model büyüğün kararına yakın kalır. Yaratıcı yazı ve açık uçlu sohbette α 0.6-0.75’e kadar düşebilir. Temperature düşük olduğunda dağılım keskinleşir ve kabul oranı yükselir; yüksek temperature’da tersi geçerlidir.
Bu oranlar draft model seçimini doğrudan etkiler. α’yı gerçekçi biçimde tahmin etmek için kendi kullanım senaryonuzdan birkaç yüz istek alıp draft token’larının kaçının kabul edildiğini loglamanız yeterli. vLLM bu metriği speculative_tokens_accepted alanında raporluyor; bu sayıyı num_speculative_tokens ile bölünce anlık α elde edilir.
Gerçek Benchmark’lar
Speculative decoding tekniğini ilk sistematik biçimde formüle eden Leviathan ve arkadaşlarının 2023 tarihli makalesi, Chinchilla 70B üzerinde 2.4x token/sn artışı bildirdi. Bu oran, verifier ve draft maliyetlerinin oranı ile acceptance rate değerlerine bağlı olduğundan modelden modele değişir.
| Yapılandırma | Standart Decoding (tok/sn) | Speculative Decoding (tok/sn) | Kazanım |
|---|---|---|---|
| Llama-3-70B (tek A100) | ~18 | ~42 | ~2.3x |
| Llama-3-70B + 8B (tek A100) | — | ~38-44 | 2.1-2.4x |
| Gemma 27B + 2B | ~28 | ~62 | ~2.2x |
Benchmark koşulları sonuçları doğrudan etkiler. Tek kullanıcılı veya düşük batch senaryolarında (geliştirici araçları, bireysel chatbot) speculative decoding en yüksek etkiyi gösterir. Aynı GPU üzerinde çalışan 100 eş zamanlı istek varsa batch’leme GPU’yu zaten verimli doldurduğundan etki azalır. Tablodaki rakamlar batch_size=1 veya düşük concurrency koşullarında üretildi; production rakamlarınız workload’a göre farklılaşır.
vLLM 0.4 sürümünden itibaren speculative decoding varsayılan olarak destekleniyor. Throughput iyileştirmesi özellikle düşük batch boyutlarında belirgin; yüksek concurrent kullanıcı trafiğinde batch’lemenin zaten GPU’yu doldurduğu durumlarda kazanım nispeten sınırlı kalır.
vLLM ile Uygulama: Çalıştırılabilir Örnek
vLLM’de speculative decoding etkinleştirmek için speculative_model parametresi yeterli:
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3.1-70B-Instruct",
speculative_model="meta-llama/Llama-3.1-8B-Instruct",
num_speculative_tokens=4, # γ = 4
speculative_draft_tensor_parallel_size=1,
)
params = SamplingParams(temperature=0.2, max_tokens=512)
outputs = llm.generate(
["Transformer mimarisinde KV cache nedir?"],
params
)
print(outputs[0].outputs[0].text)num_speculative_tokens değeri γ’ya karşılık gelir. 3-5 arasında değerler çoğu iş yükü için iyi bir başlangıç noktasıdır. Değer büyüdükçe acceptance rate düşük görevlerde net kazanım azalabilir.
HuggingFace Transformers’da aynı işlev AssistantModel API’si üzerinden yürür:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
draft_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct",
torch_dtype=torch.float16,
device_map="cuda",
)
target_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-70B-Instruct",
torch_dtype=torch.float16,
device_map="cuda",
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-70B-Instruct")
inputs = tokenizer("Speculative decoding nasıl çalışır?", return_tensors="pt").to("cuda")
outputs = target_model.generate(
**inputs,
assistant_model=draft_model,
max_new_tokens=200,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Sınırlar ve Hangi Durumda Dezavantaj?
Speculative decoding her koşulda kazandırmaz.
Yüksek concurrent yük: vLLM veya benzeri sunucular zaten yüksek batch boyutlarıyla GPU’yu dolu tutuyor. Bu durumda speculative decoding ek karmaşıklık katar, throughput kazanımı ise marjinalleşir.
Ek bellek maliyeti: Draft modeli VRAM’de tutmak gerekir. Llama-3-8B FP16’da yaklaşık 16 GB yer kaplar. Zaten dolu GPU’larda bu ek yük ciddi bir kısıt olabilir. Quantized draft modellerle (4-bit veya 8-bit) bu yük önemli ölçüde düşer.
Yaratıcı yazı ve yüksek temperature: Kabul oranı düştüğünde döngüler kısalır ve ek overhead devreye girer. α < 0.6 bandında toplam maliyet bazen standart decoding’i geçebilir.
Streaming latency: Speculative decoding throughput’u artırır ama ilk token gecikme süresini (TTFT) doğrudan iyileştirmez. Birinci token için draft döngüsü bile olsa büyük model forward pass’i zorunludur.
Çok GPU’lu dağıtımlar: Draft ve verifier farklı GPU’lara dağıtıldığında iletişim overhead’i devreye girer. Tek node içinde NVLink ile bağlı GPU’lar bu overhead’i minimize eder; farklı node’lara taşındığında ağ gecikmesi kazanımı önemli ölçüde yiyebilir. vLLM bu overhead’i speculative_draft_tensor_parallel_size parametresiyle kontrol altına alıyor: draft modeli daha az GPU’da tutarak iletişim maliyeti düşer.
Medusa ve Self-Speculative Varyantlar
Birkaç farklı mimari bu temel fikri değişik açılardan genişletti.
Medusa, ayrı bir draft modele ihtiyaç duymadan birden fazla “head” (kafa) ekleyerek çalışır. Ana transformerin son katmanına, her biri bir sonraki k. token’ı tahmin eden ek lineer kafalar bağlanır. Bu kafalar paralel olarak γ token önerir; verifier standart forward pass’le tümünü değerlendirir. Ek VRAM maliyeti sınırlıdır çünkü ana model değişmez, yalnızca küçük kafalar eklenir.
EAGLE draft modeli olarak ana modelin özellik vektörlerini girdi alan daha küçük bir otoregresif modeli kullanır. Ana modelin gizli durumlarına erişim, draft kalitesini artırır.
Hydra, Medusa’nın bir uzantısı olup kabul kriterini daha agresif biçimde optimize eder ve ağaç biçiminde token alternatifleri değerlendirir.
Medusa kullanmak için modeli yeniden fine-tune etmek gerekir; ek kafalar mevcut ağırlıklara ekleniyor ve bu kafalar için ayrı bir eğitim adımı zorunlu. Bu, off-the-shelf bir model çiftinin hemen kullanılabildiği klasik speculative decoding’den farklı bir durum. EAGLE2 ise Medusa’nın avantajlarını daha gelişmiş bir draft ağıyla birleştiriyor; 2024 benchmark’larında hem Medusa hem de vanilla speculative decoding üzerinde daha iyi sonuçlar verdi. Hangi yaklaşımın daha iyi çalıştığı model ailesine ve kullanım senaryosuna bağlı; karar vermeden önce kendi veri setinizle kısa bir benchmark koşmak faydalı olur.

Ayrı bir küçük model mevcutsa ve VRAM yeterliyse klasik speculative decoding en kolay başlangıç noktasıdır. Ek model yükü istemiyorsanız ya da fine-tuned özel bir modeliniz varsa Medusa daha pratik bir seçenek olabilir.
İlgili Rehberler
Speculative decoding, daha geniş bir LLM optimizasyon yığınının parçasıdır. vLLM Nedir? Açık Kaynak LLM Çıkarım Motoru Rehberi’nde PagedAttention ve continuous batching ile birlikte nasıl çalıştığını bulabilirsiniz. Draft model seçimindeki bellek trade-off’larını anlamak için Quantization Nedir? GGUF, AWQ, GPTQ ile Model Optimizasyonu yazısı iyi bir tamamlayıcıdır. Token düzeyinde işleyişi daha derin anlamak isteyenler için LLM Tokenization Nedir? yazısı da faydalı bir başlangıç noktası sunar.



